在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
此前,BOSS直聘研究院发布的《 2022 年春季就业市场趋势观察》指出,受到 2021 年政策调控的影响,互联网行业的高速扩张开始降温。
2022年春季,互联网行业的招聘规模虽然仍然保持增长,同比增速为 13% ,但处于 2019 年以来的低点,而求职激烈程度则高于往年。
整体上看,核心的技术和产品类岗位仍然保持着较为密集的人才需求,主要的互联网技术方向上人才需求均有增长,而运营和销售类岗位的求职者竞争则明显加剧。
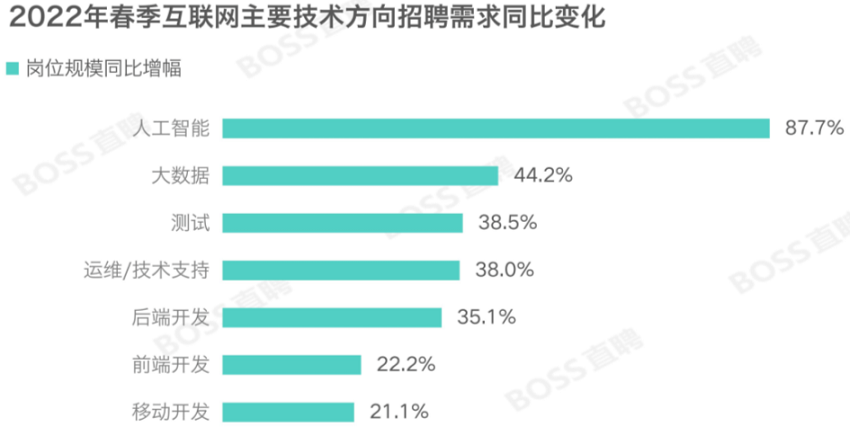
来源/ 2022 年春季就业市场趋势观察
《报告》也指出,从岗位招聘和投递的供求对比来看,互联网核心的技术/测试/运维仍保持着较为密集的人才需求,主要体现在企业对以人工智能、数字孪生为代表的高技术岗位的需求,此类岗位同比保有两位数的高增长,相关从业者仍有较大的择业空间与机会。而产品/运营/策划、销售/商务/售前、客服/审核/售后等岗位的求职竞争随着互联网“降本增效”进一步加剧。
猎聘发布的《2022未来人才就业趋势报告》也指出,大数据排名第四,年薪达到25万多,比2018年同期上涨4.87万。

图表来源:《2022未来人才就业趋势报告》
说了这么多,那么什么是大数据,大数据和我们平时看到的数据有什么区别呢?为什么大数据是是一种战略资源。
研究大数据,最重要的意义是预测。因为数据从根本上讲,是对过去和现在的归纳和总结,其本身不具备趋势和方向性的特征,但是可以应用大数据去了解事物发展的客观规律、了解人类行为,并且能够帮助我们改变过去的思维方式,建立新的数据思维模型,从而对未来进行预测和推测。比如,商业公司对消费者日常的购买行为和使用商品习惯进行汇总和分析,了解到消费者的需求,从而改进已有商品并适时推出新的商品,消费者的购买欲就会提高。
知名互联网公司谷歌对其用户每天频繁搜索的词汇进行数据挖掘,从而进行相关的广告推广和商业研究。
大数据的处理技术迫在眉睫,近年来各国政府和全球学术界都掀起了一场大数据技术的革命,众人纷纷积极研究大数据的相关技术。很多国家都把大数据技术研究上升到了国家战略高度,提出了一系列的大数据技术研发计划,从而推动政府机构、学术界、相关行业和各类企业对大数据技术进行探索和研究。
可以说大数据是一种宝贵的战略资源,其潜在价值和增长速度正在改变着人类的工作、生活和思维方式。可以想象,在未来,各行各业都会积极拥抱大数据,积极探索数据挖掘和分析的新技术、新方法,从而更好地利用大数据。当然,大数据并不能主宰一切。大数据虽然能够发现“是什么”,却不能说明“为什么”;大数据提供的是些描述性的信息,而创新还是需要人类自己来实现。
根据《数据时代2025》白皮书预测:2025年,全球数据量将达到史无前例的163ZB 。
Kevin Kelly曾经这样预言:“大数据时代,没有人能够成为旁观者,数据将横扫一切。”。
随着大数据的不断普及,未来将会有更多的行业与之相结合,从而创造出更多的就业岗位,无论是比较火的金融、互联网等行业,还是像医疗、教育、城市规划等方面,都将需要大量的大数据人才。
你是否对人工智能,大数据感觉好奇甚至想转个行,相对来讲,转行做大数据工程师更容易。
关于学习大数据,这里有一个学习路线图,你可以进行参考:
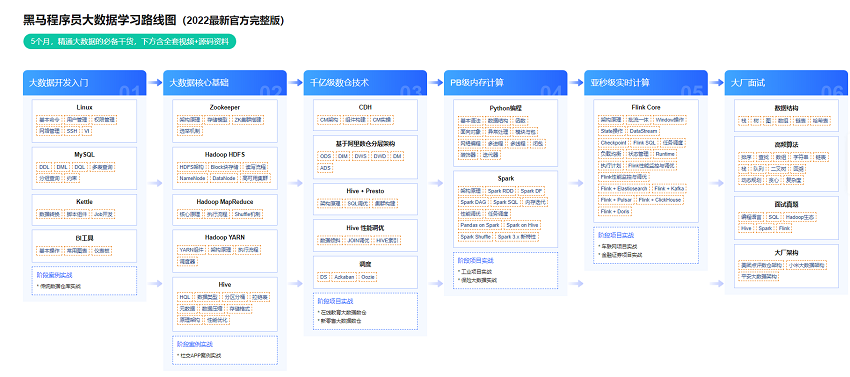
简单来说,分为6步,大数据开发入门,大数据核心基础,千亿级数仓技术,PB级内存计算,亚秒级实时计算,大厂面试。
第一阶段:大数据开发入门
MySQL数据库及SQL语法
MySQL可以处理拥有上千万条记录的大型数据库,使用标准的SQL数据语言形式,MySQL可以安装在不同的操作系统,并且提供多种编程语言的操作接口,这些编程语言包括C、C++、Python、Java、Ruby等等。支持多种存储引擎。
Kettle与BI工具
Kettle作为一个端对端的数据集成平台,其部分特色功能包括:无代码拖拽式构建数据管道、多数据源对接、数据管道可视化、模板化开发数据管道、可视化计划任务、深度Hadoop支持、数据任务下压Spark集群、数据挖掘与机器学习支持。
Python与数据库交互
实际的生产任务中,数据几乎全部存在与数据库中,因此,与数据库的交互成为一件难以避免的事情。想要在Python代码中和MySQL数据库进行交互,需要借助一个第三方的模块“Pymysql”
第二阶段:大数据核心基础
Linux
Linux 作为操作系统,本身是为了管理内存,调度进程,处理网络协议栈等等。
而大数据的发展是基于开源软件的平台,大数据的分布式集群( Hadoop,Spark )都是搭建在多台 Linux 系统上,对集群的执行命令都是在 Linux 终端窗口输入的。
据Linux基金会的研究,86%的企业已经使用Linux操作系统进行大数据平台的构建。Linux占据优势。
Hadoop基础
Hadoop是一个能够对大量数据进行分布式处理的软件框架。Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
它很擅长存储大量的半结构化的数据集。也非常擅长分布式计算——快速地跨多台机器处理大型数据集合。
Hadoop的框架核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
MapReduce和Hadoop是相互独立的,实际上又能相互配合工作得很好。MapReduce是处理大量半结构化数据集合的编程模型。
大数据开发Hive基础
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。Hive十分适合对数据仓库进行统计分析。
第三阶段:千亿级数仓技术
企业级在线教育项目实战
Hive数仓项目完整流程,以真实项目为驱动,学习离线数仓技术。
建立集团数据仓库,统一集团数据中心,把分散的业务数据集中存储和处理 ;从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序 ;挖掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。
第四阶段:PB内存计算
Python编程基础+进阶
Python是基于ABC语言的发展来的,Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言, 随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
Python语言的语法非常简洁明了,即便是非软件专业的初学者,也很容易上手。
和其它编程语言相比,实现同一个功能,Python 语言的实现代码往往是最短的。
Spark技术栈
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。
Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
大数据Flink技术栈
Flink核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。基于流执行引擎,Flink提供了诸多更高抽象层的API以便用户编写分布式任务。
Flink也可以方便地和Hadoop生态圈中其他项目集成,例如Flink可以读取存储在HDFS或HBase中的静态数据,以Kafka作为流式的数据源,直接重用MapReduce或Storm代码,或是通过YARN申请集群资源等。
Spark离线数仓工业项目实战
通过大数据技术架构,解决工业物联网制造行业的数据存储和分析、可视化、个性化推荐问题。一站制造项目主要基于Hive数仓分层来存储各个业务指标数据,基于sparkSQL做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料。
好了,以上就是大数据的前景和学习路线介绍,希望对你有所帮助。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
大数据行业现在工作好不好找?很难吗?
下一篇:
数据分析行业到底有多卷
相关推荐 更多

数据库开发转行大数据开发工程师怎么样?
数据库开发转行大数据开发工程师怎么样?大数据的方向的工作有大数据运维工程师、大数据开发工程师、数据分析、数据挖掘、架构师等。有工作经验想转行大数据开发主要考察基础、学习能力、解决问题的能力。
9332
2019-05-20 17:54:38

大数据工程师需要具备哪些能力?
大数据工程师需要具备哪些能力?这是许多想在大数据时代把握住发展机遇的学习者,在学习大数据前共同关心的问题。其实任何一个岗位需要具备的能力无外乎两种,即在专业领域的硬实力和职场发展上的软实力。对于大数据行业来讲,要向具备其相应的专业能力,需要学习的内容有很多。下面我就来为大家一一分析,大数据工程师需要具备的各项能力和掌握的各项知识。
9248
2020-01-16 17:03:43

数据仓库与数据库的区别是什么?
相信大数据学习者对于数据仓库与数据库并不陌生,两者都是通过数据库软件实现存放数据的地方,从这个意义上来看,它们似乎没有多大的差别。但是再深入一点分析,我们会发现无论是从数据量还是作用来讲,两者的区别都是巨大的。为了更清楚的分辨数据仓库与数据库,下面我们具体来聊聊数据仓库与数据库的区别。
15226
2020-06-05 11:06:23
Hadoop HDFS分布式文件系统原理及应用介绍
HDFS有着高容错性特点,且设计用来部署在低廉的硬件上,提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了POSIX的要求,可以实现流的形式访问文件系统中的数据。
4019
2021-04-13 16:30:33

大数据spark框架常用数据类型RDD与DataFrame的区别
大数据spark框架常用数据类型RDD与DataFrame的区别,在spark中,RDD、DataFrame是最常用的数据类型,在Apache Spark 里面DF 优于RDD但也包含了RDD的特性,在使用的过程中分别介绍下两者的区别和各自的优势。
2930
2022-04-19 11:12:45



