在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
HDFS有着高容错性特点,且设计用来部署在低廉的硬件上,提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了POSIX的要求,可以实现流的形式访问文件系统中的数据。
Hadoop分布式文件系统HDFS是一种被设计成适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。它能提供高吞吐量的数据访问非常适合大规模数据集上的应用。
HDFS概念
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件, 并且提供统一的访问接口。
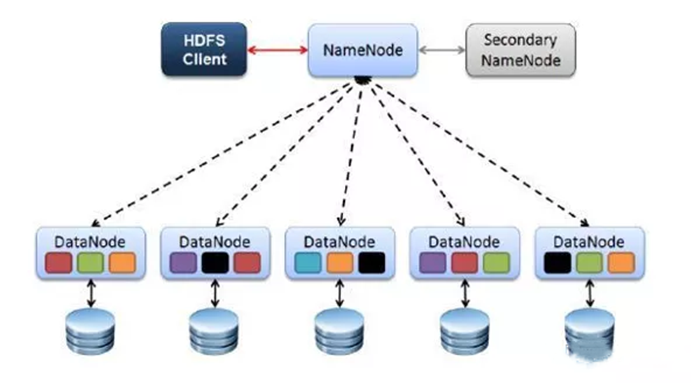
HDFS的四个基本组件:HDFS Client、NameNode、DataNode和Secondary NameNode。
HDFS采用主从结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。
Client
Client是客户端。HDFS Client文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
NameNode
NameNode就是 master,它是一个主管、管理者。管理 HDFS 元数据(文件路径,文件的大小,文件的名字,文件权限,文件的block切片信息)。
NameNode管理 Block 副本策略:默认 3 个副本,处理客户端读写请求。
DataNode
DataNode就是Slave。NameNode下达命令,DataNode 执行实际的操作。DataNode存储实际的数据块,执行数据块的读/写操作。定时向namenode汇报block信息。
Secondary NameNode
SecondaryNameNode不是NameNode的备份。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
辅助 NameNode,分担其工作量。在紧急情况下,可辅助恢复 NameNode。
副本机制
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
在hadoop2 当中, 文件的 block 块大小默认是 「128M」(134217728字节)。

如图所示,一个大小为300M的a.txt上传到HDFS中,需要进行128M的切分,不足128M分为到另一block中。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
觉得不错,顺手分享一下 
微信扫一扫
上一篇:
大数据开发培训哪家好?怎么选?
下一篇:
机器学习在线学习网站哪个好?
相关推荐 更多

互联网医疗大数据商业变现应用
互联网医疗大数据商业变现应用,2018年《国家健康医疗大数据标准、安全、服务管理办法(试行)》正式出炉,与以往政策不同,该规定不再停留于宏观指导层面,而是对医疗大数据标准、安全、服务中的权责利进行了详细规定。
8272
2019-04-18 18:12:28

如何激活conda环境?conda创建新环境步骤教程
如何激活conda环境?针对这个问题,本教程将手把手按照创建、激活、查看活跃的环境三个步骤教大家conda创建新环境。
28400
2019-08-07 15:38:03

大数据Kafka进阶面试题汇总
Kafka是一个分布式、支持分区的、多副本的,基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景。在大数据面试中,Kafka也是一个必考点。因此小编汇总了历年来比较经典常见的大数据Kafka进阶面试题。
5956
2019-08-22 19:26:09

数据分析应用在哪些领域?都起到了什么作用?
随着大数据的发展,数据分析早已渗透各行业各业,尤其是互联网、电商和金融三大行业。同时数据分析在电信、旅游、医疗健康等等领域,也有比较多的应用。下面我们来看看在这些领域数据分析究竟起了什么作用。
12554
2019-09-28 09:54:27

HDFS安全模式学习总结
众所周知,安全模式是HDFS所处的一种特殊状态,今天我们要来梳理一下关于HDFS安全模式的学习总结,主要内容包括安全模式概述、安全模式配置以及安全模式命令。下面赶紧开始吧~
4501
2020-06-05 17:05:28










