在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
大数据spark框架常用数据类型RDD与DataFrame的区别,在spark中,RDD、DataFrame是最常用的数据类型,在Apache Spark 里面DF 优于RDD但也包含了RDD的特性,在使用的过程中分别介绍下两者的区别和各自的优势。

1、RDD是什么?
RDD(Resilient Distributed Datasets)提供了一种高度受限的共享内存模型。即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和group by)而创建,然而这些限制使得实现容错的开销很低。RDD仍然足以表示很多类型的计算,包括MapReduce和专用的迭代编程模型(如Pregel)等。
RDD五大特点:(必须的)可分区的: 每一个分区对应就是一个Task线程;(必须的)计算函数(对每个分区进行计算操作);(必须的)存在依赖关系;(可选的)对于key-value数据存在分区计算函数;(可选的)移动数据不如移动计算(将计算程序运行在离数据越近越好)。
2、DataFrame是什么?
DataFrame是一种分布式的数据集,并且以列的方式组合的。类似于关系型数据库中的表。可以说是一个具有良好优化技术的关系表。DataFrame背后的思想是允许处理大量结构化数据。提供了一些抽象的操作,如select、filter、aggregation、plot。DataFrame包含带schema的行。schema是数据结构的说明。相当于具有schema的RDD。
DataFrame特性:支持从KB到PB级的数据量;支持多种数据格式和多种存储系统;通过Catalyst优化器进行先进的优化生成代码;通过Spark无缝集成主流大数据工具与基础设施;API支持Python、Java、Scala和R语言。
3、RDD和DataFrame有什么区别?
RDD是弹性分布式数据集,数据集的概念比较强一点。容器可以装任意类型的可序列化元素(支持泛型)
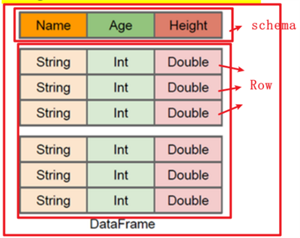
RDD的缺点是无从知道每个元素的【内部字段】信息。意思是下图不知道Person对象的姓名、年龄等。

DataFrame也是弹性分布式数据集,但是本质上是一个分布式数据表,因此称为分布式表更准确。DataFrame每个元素不是泛型对象,而是Row对象。
DataFrame的缺点是Spark SQL DataFrame API 不支持编译时类型安全,因此,如果结构未知,则不能操作数据;同时,一旦将域对象转换为Data frame ,则域对象不能重构。
DataFrame=RDD-【泛型】+schema+方便的SQL操作+【catalyst】优化DataFrame本质上是一个【分布式数据表】
DataFrame优于RDD,因为它提供了内存管理和优化的执行计划。总结为以下两点:
a.自定义内存管理:当数据以二进制格式存储在堆外内存时,会节省大量内存。除此之外,没有垃圾回收(GC)开销。还避免了昂贵的Java序列化。因为数据是以二进制格式存储的,并且内存的schema是已知的。
b.优化执行计划:这也称为查询优化器。可以为查询的执行创建一个优化的执行计划。优化执行计划完成后最终将在RDD上运行执行。
4、RDD与DataFrame个字有什么特性?
在Apache Spark 里面DF 优于RDD,但也包含了RDD的特性。
RDD和DataFrame的共同特征是不可性、内存运行、弹性、分布式计算能力。它允许用户将结构强加到分布式数据集合上。因此提供了更高层次的抽象。
从不同的数据源构建DataFrame。例如结构化数据文件、Hive中的表、外部数据库或现有的RDDs。DataFrame的应用程序编程接口(api)可以在各种语言中使用,包括Python、Scala、Java和R。
DataFrame API能够提高spark的性能和扩展性,避免了构造每行在dataset中的对象造成GC的代价。不同于RDD API能构建关系型查询计划更加有有利于熟悉执行计划的开发人员,同理不一定适用于所有人。
拿高薪入行大数据,选择《狂野大数据》课程,抓住大数据时代的“薪”机遇!!

— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
转大数据技术开发要学哪些知识点?高效的大数据学习路线推荐
下一篇:
累加器和广播变量分别在什么场景使用?
相关推荐 更多

实现大数据可视化的十个出发点
实现大数据可视化的十个出发点,需要考虑用户、讲述连贯的故事、迭代设计、个性化一切、从分析目标开始、考虑管理、对观看者的同理心、了解业务、连接可视化、尽可能简化,以便解决手头的假设问题。
12081
2019-04-24 19:16:12

科普Spark,什么是Spark?
Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
9596
2019-07-09 12:04:57

Kylin开发教程 从原理讲解到实践演练
众所周知,Kylin是一个可扩展的超快OLAP引擎,它能够提供Hadoop ANSI SQL借口和交互式查询,还可以和BI工具无缝整合,为百亿用户构建立方体。既然学习Kylin这么有必要,那么我们该如何学习它呢?这里为大家介绍博学谷的Kylin开发教程,本教程将会对Kylin进行系统化梳理,包括了Kylin的技术架构、运维不熟、增量构建、实时构建、性能优化等内容,带领大家从原理讲解到实战演练。
6452
2019-11-25 12:22:09

大数据在零售供应链管理方面的应用
零售商可通过多种方式使用大量信息来改善其零售供应链,分析解决方案将供应商的实际绩效与其关键绩效指标进行比较,帮助供应商在按时交货、提升客户满意度等。
5750
2020-12-31 10:38:03

学习大数据前应该了解什么?
大数据学习不能停留在理论的层面上,大数据方向切入应是全方位的,基础语言的学习只是很小的一个方面,编程落实到最后到编程思想。学习前一定要对大数据有一个整体的认识。
4754
2021-01-06 10:19:34



