在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
缓存是什么?为什么要使用缓存?缓存是将一些需要读取数据放在磁盘或者内存中,在读取数据的时一般是从关系型数据库中读取数据,缓存时能够最快提高服务响应速度的优化。
一、缓存是什么?
缓存就是将一些需要读取数据放在磁盘或者内存中,由于是追求速度,从而一般放在内存中。在读取数据的时候,一般是从关系型数据库中读取数据,在数据库层面也可以进行各种优化,例如读性能不足,那么可以添加几个从库,从而数据库的一主多从;例如写性能不足,那么可以分库分表。
在有些场景中,要使用缓存,是因为无法解决读的速度,例如count(*)的操作,无论从数据库的层面如何优化,都不可能提高;还有一种就是sql的执行本身就必须消耗很多资源和时间,例如各种关联查询子查询,这些时候,都可以将这些数据放在缓存当中,从而大大的减轻数据库的压力。
二、业务中为什么要使用缓存?
缓存时能够最快提高服务响应速度的优化,没有之一.
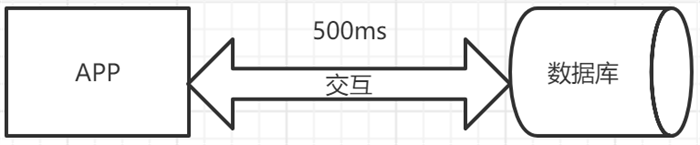
如上图的应用程序直接连接数据库进行查询操作,假如有一个操作过来需要500ms,并且每一次查询都需要经过数据库,性能非常低,并且对于数据库并发量支持非常不友好,如果并发量太多导致数据库压力太大可能导致数据库崩溃或者卡死。
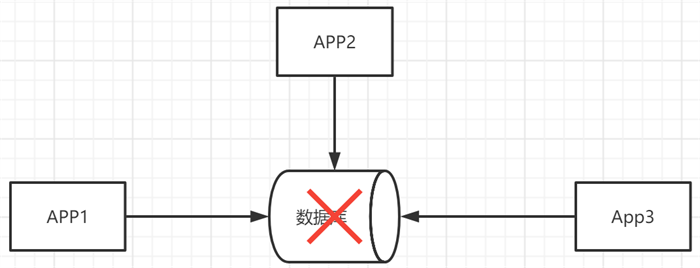
如果数据库崩溃,则依赖于数据库的其他应用都会无法运行。
1、高性能
这个是大部分使用缓存的目的,能够最快以非常高的效率提高应用的性能假设遇到一些查询速度很慢,比如权限,查询速度很慢,并且查询出来后很少发生变化,这种情况下大量查询对数据压力很大,并且性能不高。
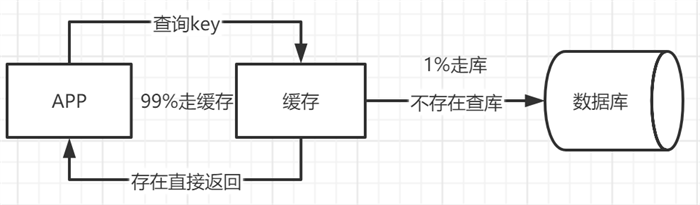
我们将缓存中的key保存到缓存中,然后在需要查询的时候直接查询缓存,而不走数据库,这样响应数据非常快,并且对于数据库的压力很小,一般缓存的查询都在微秒级,分布式缓存Redis中查询数据也在1ms中可以查询出来,这样在系统架构不进行大的变化的情况下完成了500倍的性能提升。
所以对于一些需要复杂操作耗时查出来的结果,确定后面不怎么变化,但是有很多读请求,直接将查询出来的结果放在缓存中,后面直接读缓存就好。
2、高并发
mysql 数据库对于高并发来说天然支持不好,mysql 单机支撑到 2000QPS 也开始容易报警了。
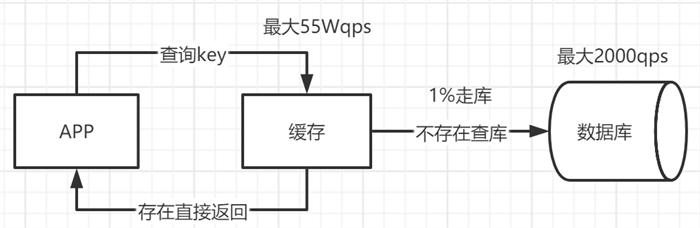
所以若是系统高峰期一秒钟有1万个请求,那么一个 mysql 单机绝对会死掉,这个时候就只能上缓存,把很多数据放入缓存,别放入 mysql,缓存功能简单,说白了就是 key-value 式操作,单机支撑的并发量一秒可达几万十几万,单机承载并发量是 mysql 单机的几十倍。
3、收益与成本
3.1收益
通过缓存加速读写速度:在内存中读写比硬盘速度快;降低数据库服务器的负载:比如业务端的请求的数据大多数都由Redis服务器来处理,大大减轻MySQL服务器的压力。
3.2 成本
数据不一致问题:比如Redis服务器与数据库服务器之间的某些数据可能会发生不一致问题,这是由两个服务器的数据更新策略不同引起的。
代码维护成本:需要添加数据缓存的逻辑代码;
运维成本:比如需要维护RedisCluster。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
大数据战略对企业生存有多重要?
下一篇:
缓存如何分类?有什么区别?
相关推荐 更多

数据仓库和数据挖掘的有什么联系和区别?
数据仓库和数据挖掘的有什么联系和区别?首先我们要清楚数据仓库是一个实现数据存放庞大的地方,而数据挖掘是从海量的数据中提取数据。因此这两者在本质上就存在明显的区别,不过两者既相互区别又相互联系,数据仓库和数据挖掘都可以看做是商业智能工具集合。下面我们来好好认识一下数据仓库和数据挖掘的定义、联系和区别吧!
10628
2020-01-12 17:13:04

物联网怎么保护云计算安全?
全球应用的物联网设备已经达到数十亿台,且数量不断增加。在开发和部署的许多物联网设备却缺乏关键的安全功能为黑客和僵尸网络的目标。没有适当的安全措施,物联网设备会导致灾难性事件。如何解决这些问题呢?
6735
2020-03-23 17:51:20

大数据培训需要什么基础吗?
随着2020年大数据的应用在各个领域的落地发展,大数据技术成为各大企业公司竞争的新焦点,就业市场对于大数据人才的需求也在持续扩大。相信不少大数据初学者都好奇,大数据培训需要什么基础吗?以博学谷的培训经验来看,大多数学员都是从零基础开始学习,并不一定需要什么相关技术的基础。当然,Java在大数据开发方面十分有优势,也是大数据课程必学的编程语言,具备Java编程基础可以节省不少学习时间。
6700
2020-06-15 10:55:54

Sequence File格式是什么?如何使用?
Hadoop可以存储多种文件格式。sequenceFile文件是Hadoop用来存储二进制形式的[Key,Value]对而设计的一种平面文件(Flat File)。可以把SequenceFile当做是一个容器,把所有的文件打包到SequenceFile类中可以高效的对小文件进行存储和处理。
7394
2021-03-16 13:59:21

工信部测算到2025年中国大数据产业规模将突破3万亿元
工信部测算到2025年中国大数据产业规模将突破3万亿元,全球互联网、大数据、云计算、数字孪生、元宇宙等数字技术加速创新趋势,探讨数字科技革命和产业变革的新机遇,聚焦大数据与实体经济、社会治理、民生服务、乡村振兴的深度融合,发布一批大数据创新应用场景,探讨共享应用场景创新的价值。
4434
2022-06-09 15:29:53



