在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
Pandas如何分块处理大文件?在处理快手的用户数据时,碰到600M的txt文本,用sublime打开蹦了,用pandas.read_table()去读竟然花了小2分钟,打开有3千万行数据。仅仅是打开,要处理的话不知得多费劲。
解决:读取文件的函数有两个参数:chunksize、iterator。原理分多次不一次性把文件数据读入内存中。
1.指定chunksize分块读取文件
read_csv 和 read_table 有一个 chunksize 参数,用以指定一个块大小(每次读取多少行),返回一个可迭代的 TextFileReader 对象。
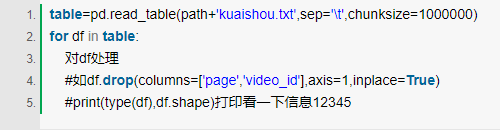
对文件进行了划分,分成若干个子文件分别处理(to_csv也同样有chunksize参数)
2.指定iterator=True

直接看pandas文档相关的内容。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
数据可视化常用工具推荐
下一篇:
零基础能学大数据技术吗?学完能找到工作吗?
相关推荐 更多

为什么大数据和云计算备受关注,大数据与云计算的关系
互联网技术不断突破与革新,大数据和云计算的概念现在已经成为互联网的热门词汇。为什么大数据和云计算这样备受关注呢?他们之间有什么关系?相信很多小伙伴也存在这样的疑问。
7750
2019-06-12 17:36:02

大数据核心技术:spark学习总结
想要学习大数据,一定要充分掌握大数据的核心技术:Hadoop、Strom、spark等等。Spark是一种与Hadoop像是的开源集群计算环境。它启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
9932
2019-06-19 17:37:43

大数据开发和软件开发哪个前景好?
大数据开发学习有难度,零基础入门要先学习Java语言打基础,然后进入大数据技术体系的学习,学习Hadoop、Spark、Storm等知识。软件开发工程师根据不同的学科从事的岗位也千差万别。
5757
2020-10-15 09:41:45

数据分析师岗位要掌握哪些编程语言?
数据分析师工作流程简化描述成数据获取整理-数据分析-生成数据报告几个关键环节,数据分析师最常用的工具Excel和Python,Excel适用一些数据量并不大还有它的重复性并不算强的大量的工作场景,使用Python语言对大量的数据进行更深入、更强大的数据分析。
4718
2021-03-19 16:36:50

如何解决HBase海量数据高效入仓的问题?
如何解决HBase海量数据高效入仓的问题?数据仓库的数据来源于各方业务系统,高效准确的将业务系统的数据同步到数仓是数仓建设的根本。部分业务数据存储在HBase中,这部分数据体量较大达到数十亿。大数据需要增量同步这部分业务数据到数据仓库中进行离线分析,目前主要的同步方式是通过HBase的hive映射表来实现的。
2889
2022-03-10 13:46:02



