在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
大数据发展到今天,已经是越来越成熟,无论是大型互联网公司,还是小型的创业公司,都能看见大数据的身影。那么,学习大数据必须掌握哪些核心技术呢?

一、数据采集与预处理
数据采集就是将这些包括移动互联网数据、社交网络的数据等各种来源的数据,写入数据仓库中,把零散的数据整合在一起,对这些数据进行综合分析。
Flume NG作为实时日志收集系统,支持在日志系统中定制各类数据发送方,用于收集数据,同时,对数据进行简单处理,并写到各种数据接收方(比如文本,HDFS,Hbase等)。
NDC,Netease Data Canal,直译为网易数据运河系统,是网易针对结构化数据库的数据实时迁移、同步和订阅的平台化解决方案。
Logstash是开源的服务器端数据处理管道,能够同时从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。
Sqoop,用来将关系型数据库和Hadoop中的数据进行相互转移的工具,可以将一个关系型数据库(例如Mysql、Oracle)中的数据导入到Hadoop(例如HDFS、Hive、Hbase)中,也可以将Hadoop(例如HDFS、Hive、Hbase)中的数据导入到关系型数据库(例如Mysql、Oracle)中。
Strom集群结构是有一个主节点(nimbus)和多个工作节点(supervisor)组成的主从结构,主节点通过配置静态指定或者在运行时动态选举,nimbus与supervisor都是Storm提供的后台守护进程,之间的通信是结合Zookeeper的状态变更通知和监控通知来处理。
Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,提供数据同步服务。
二、数据存储
Hadoop作为一个开源的框架,专为离线和大规模数据分析而设计,HDFS作为其核心的存储引擎,已被广泛用于数据存储。
HBase,是一个分布式的、面向列的开源数据库,可以认为是hdfs的封装,本质是数据存储、NoSQL数据库。
Phoenix,相当于一个Java中间件,帮助开发工程师能够像使用JDBC访问关系型数据库一样访问NoSQL数据库HBase。
Yarn是一种Hadoop资源管理器,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
Mesos是一款开源的集群管理软件,支持Hadoop、ElasticSearch、Spark、Storm 和Kafka等应用架构。
Redis是一种速度非常快的非关系数据库,可以存储键与5种不同类型的值之间的映射,可以将存储在内存的键值对数据持久化到硬盘中,使用复制特性来扩展性能,还可以使用客户端分片来扩展写性能。
Atlas是一个位于应用程序与MySQL之间的中间件。
Kudu是围绕Hadoop生态圈建立的存储引擎,Kudu拥有和Hadoop生态圈共同的设计理念,它运行在普通的服务器上、可分布式规模化部署、并且满足工业界的高可用要求。
三、数据清洗
MapReduce作为Hadoop的查询引擎,用于大规模数据集的并行计算,”Map(映射)”和”Reduce(归约)”,是它的主要思想。它极大的方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统中。
随着业务数据量的增多,需要进行训练和清洗的数据会变得越来越复杂,这个时候就需要任务调度系统,比如oozie或者azkaban,对关键任务进行调度和监控。
四、数据查询分析
Hive的核心工作就是把SQL语句翻译成MR程序,可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能。
Hive是为大数据批量处理而生的,Hive的出现解决了传统的关系型数据库(MySql、Oracle)在大数据处理上的瓶颈
Impala是对Hive的一个补充,可以实现高效的SQL查询。使用Impala来实现SQL on Hadoop,用来进行大数据实时查询分析。
Spark拥有Hadoop MapReduce所具有的特点,它将Job中间输出结果保存在内存中,从而不需要读取HDFS。Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬虫。
Solr用Java编写、运行在Servlet容器(如Apache Tomcat或Jetty)的一个独立的企业级搜索应用的全文搜索服务器。
Elasticsearch是一个开源的全文搜索引擎,基于Lucene的搜索服务器,可以快速的储存、搜索和分析海量的数据。
五、数据可视化
对接一些BI平台,将分析得到的数据进行可视化,用于指导决策服务。主流的BI平台比如,国外的敏捷BI Tableau、Qlikview、PowrerBI等,国内的SmallBI和新兴的网易有数等。
大数据技术的体系庞大且复杂,每年都会涌现出大量新的技术,目前大数据行业所涉及到的核心技术主要就是:数据采集、数据存储、数据清洗、数据查询分析和数据可视化。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
常见的推荐算法原理介绍
下一篇:
有程序员我不当,我要当年薪40万的农民工!
相关推荐 更多

大数据Hadoop集群搭建步骤讲解
相信每一个大数据学习者都明白,Hadoop在大数据中的重要地位。Hadoop简称HDFS,它是是大数据的基础,所以大家一定要掌握好Hadoop的相关基础知识。本文主要是详细讲解Hadoop集群的基本概念、搭建步骤及注意事项。
6663
2019-08-22 16:18:16
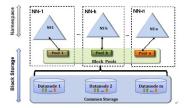
Hadoop的联邦机制 大数据学习总结
Hadoop的NN所使用的资源受所在服务的物理限制,不能满足实际生产需求。本文来谈谈大数据学习之Hadoop的联邦机制,主要内容包括:Hadoop的局限与不足、联邦的实现、主要优点、配置和操作。
6647
2019-08-27 20:31:19

企业大数据竞争优势有哪些?
企业大数据竞争优势:企业利用大数据可以进行目标客户细分、提高效率降低成本、筛选优秀人才、制定有效策略。在大数据时代,使用数据分析的手段很关键,通过数据分析才能带来价值。
6026
2020-04-28 16:44:45

学大数据一定要学Java编程语言吗?
大数据相关岗位的就业薪资和发展前景,吸引了许多人纷纷参加培训机构以谋求一个就业机会。考察各个培训机构的课程,我们不难发现,不管哪个大数据培训机构的课程都涉及Java编程语言的学习。那么,学大数据一定要学Java编程语言吗?答案是不一定,如果你想从事大数据开发岗位,那一定要学Java编程语言。如果只是想往数据分析方向发展,那么学Python就足够了。
5646
2020-06-30 18:38:45

大数据spark框架常用数据类型RDD与DataFrame的区别
大数据spark框架常用数据类型RDD与DataFrame的区别,在spark中,RDD、DataFrame是最常用的数据类型,在Apache Spark 里面DF 优于RDD但也包含了RDD的特性,在使用的过程中分别介绍下两者的区别和各自的优势。
3030
2022-04-19 11:12:45



