在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
今天本文要讲解的是Hadoop集群动态扩容的内容,那么什么是动态扩容呢?数据量随着公司业务的增长越来越大,原有的datanode节点的容量,已经不能满足存储数据的需求,需要在原有集群基础上,动态添加新的数据节点,这就是我们说的动态扩容。下面一起来看看基础准备、添加datanode、datanode负载均衡服务、添加nodemanager等相关内容吧~

1、基础准备
在基础准备部分,主要是设置 hadoop 运行的系统环境
修改新机器系统 hostname(通过/etc/sysconfig/network 进行修改)
[root@node-4 ~]# cat /etc/sys conf 1g/network
NE TWORKING=yes
HOS TNAME=node -4
[r oot@node-4 ~ ] #
修改 hosts 文件,将集群所有节点 hosts 配置进去(集群所有节点保持hosts文件统一)
rootenode-1 -]# cat /etc/hosts
127.0.0.1 localhost localhost. localdomain localhost4 localhost4. local domain4
: :1 localhost localhost. localdomain localhost6 localhost6. local domain6
192.168.227.151 node-1
192.168.227.152 node-2
192.168.227.153 node-3
192.168.227.154 node-4
rootenode-1 ~]#
设置 NameNode 到 DataNode 的免密码登录(ssh-copy-id 命令实现)
修改主节点 slaves 文件,添加新增节点的 ip 信息(集群重启时配合一键启动脚本使用)
[root@node-1 J]# vim /export/servers/hadoop-2 .6. 0-cdh5.14.0/etc/hadoop/s laves
node-1
node-2
node-3
node-4
在新的机器上上传解压一个新的hadoop安装包,从主节点机器上将hadoop的所有配置文件,scp到新的节点上。
2、添加datanode
在namenode所在的机器的/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop 目录下创建 dfs.hosts 文件
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim dfs.hosts
添加如下主机名称(包含新服役的节点)
node-1
node-2
node-3
node-4
在 namenode 机器的 hdfs-site.xml 配置文件中增加 dfs.hosts 属性
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop vim hdfs-site.xml
<property>
<name>dfs.hosts</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts</value>
</property>
dfs.hosts 属性的意义:命名一个文件,其中包含允许连接到namenode的主机列表。必须指定文件的完整路径名。如果该值为空,则允许所有主机。相当于一个白名单,也可以不配置。
在新的机器上单独启动datanode:hadoop-daemon.sh start datanode
[root@node-4 ~]# hadoop-daemon.sh start datanode
starting datanode: logging to /export /servers/hadoop-2.6.0-cdh514 .0/ lops /hadoop root datanode -node-4 out
[root@node-4 ~]#
刷新页面就可以看到新的节点加入进来了
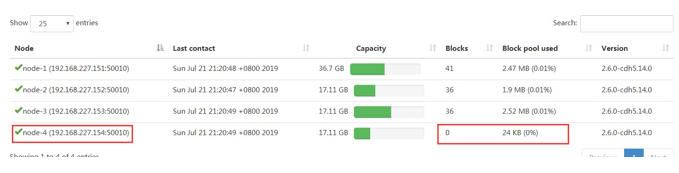
3、datanode负载均衡服务
新加入的节点,没有数据块的存储,使得集群整体来看负载还不均衡。因此最后还需要对hdfs负载设置均衡,因为默认的数据传输带宽比较低,可以设置为64M,即hdfs dfsadmin -setBalancerBandwidth 67108864即可
默认balancer的threshold为10%,即各个节点与集群总的存储使用率相差不超过10%,我们可将其设置为5%。然后启动Balancer,sbin/start-balancer.sh -threshold 5,等待集群自均衡完成即可。
4、添加nodemanager
在新的机器上单独启动 nodemanager:
yarn-daemon.sh start nodemanager
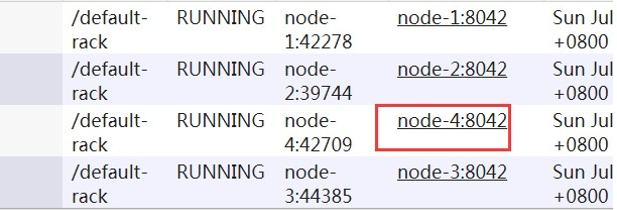
在ResourceManager,通过yarn node -list查看集群情况

以上就是Hadoop集群动态扩容讲解的全部内容,如果你还想更加深入的学习相关内容,可以报名博学谷的大数据课程,在线学习相关视频课程,还有在线讲师一对一为你答疑解惑!
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
HDFS安全模式学习总结
下一篇:
分布式系统学习笔记
相关推荐 更多

大数据核心技术:Hadoop与spark
大数据学习需要掌握很多技术知识点,包括Linux、Zookeeper、Hadoop、Redis、HDFS、MapReduce、Hive、lmpala、Hue、Oozie、Storm、Kafka、Spark、Scala、SparkSQL、Hbase、Flink、机器学习等。今天主要和大家分享一下Hadoop和spark技术。
9210
2019-06-26 17:59:29

参加大数据培训班能找到工作吗?
在大数据就业火热的背景下,许多人想要去参加大数据培训,那么参加云计算大数据培训班能找到工作吗?相信这是大家都十分关注的问题。答案是当然能,英雄不问出身,只要是真正学到了技术,还怕参加了大数据培训找不到工作吗?
10326
2019-07-30 16:44:35

学数据挖掘技术能做哪些工作?可以从事哪些行业?
学数据挖掘技术能做哪些工作?可以从事哪些行业?随着大数据时代的来临,大数据早已渗透我们生活和工作的方方面面。尤其是数据挖掘更是被各行各业广泛应用,像互联网、电商、金融、医疗等等行业对掌握数据挖掘技术的人才更是有着相当优渥的报酬。至于数据挖掘的相关岗位更是选择多多,下面来具体了解一下吧!
11856
2019-10-15 10:29:58

数据科学的发展历程
如今,数据科学可以说是一个十分火爆的领域,我们可以看到数据科学在各行各业都得到了广泛的应用。虽然数据科学在近几年发展得如此迅猛,但是数据科学的核心技术其实早在很久以前就已经提出来了。比如数据挖掘、Hadoop、深度学习、神经网络、数据可视化、强化学习和云计算等等技术都是推动数据科学发展进程的核心手段,下面我们一起来看看吧!
12344
2020-03-26 15:36:30

Hadoop入门基础知识总结
大数据时代的浪潮袭来,Hadoop作为一种用来处理海量数据分析的工具,是每一个大数据开发者必须要学习和掌握的利器。本文总结了Hadoop入门基础知识,主要包括了Hadoop概述、Hadoop的发展历程和Hadoop的特性。下面一起来看看吧!
7961
2020-06-18 10:14:31



