在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
掌握数据库已经成为了每个程序员的必备基本技能,今天我们就来带大家彻彻底底弄数据库原理的相关知识点,内容包括了事务、并发一致性、封锁、隔离级别、多版本并发控制和Next-Key Lock。希望本文全面的讲解可以一次性解决大家关于数据库原理的所有疑问。
1、事务
(1)定义
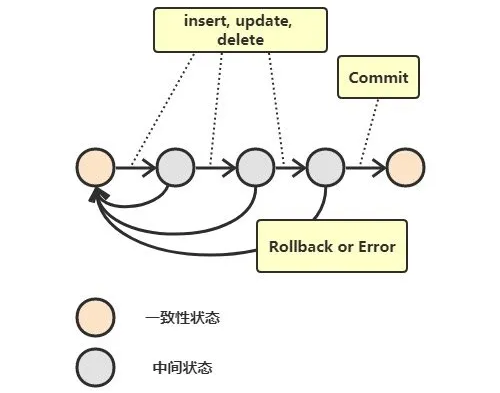
事务指的是满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。
(2)特性
A.原子性
事务被视为不可分割的最小单元,事务的所有操作要么全部提交成功,要么全部失败回滚。回滚可以用回滚日志来实现,回滚日志记录着事务所执行的修改操作,在回滚时反向执行这些修改操作即可。
B.一致性
数据库在事务执行前后都保持一致性状态。在一致性状态下,所有事务对一个数据的读取结果都是相同的。对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性;如果能容忍后续的部分或者全部访问不到,则是弱一致性**;如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
C.隔离性
一个事务所做的修改在最终提交以前,对其它事务是不可见的。
D.持久性
一旦事务提交,则其所做的修改将会永远保存到数据库中。即使系统发生崩溃,事务执行的结果也不能丢失。
2、并发一致性
(1)丢失更新
T1 和 T2 两个事务都对一个数据进行修改,T1 先修改,T2 随后修改,T2 的修改覆盖了 T1 的修改。这里举个飞机订票系统的例子方便大家了解:甲售票点(甲事务)读出某航班的机票余额A,设A=16;乙售票点(乙事务)读出同一航班的机票余额A,也为16;甲售票点卖出一张机票,修改余额A←A-1。所以A为15,把A写回数据库;乙售票点也卖出一张机票,修改余额A←A-1。所以A为15,把A写回数据库。结果明明卖出两张机票,数据库中机票余额只减少1。
(2)不可重复读
T2 读取一个数据,T1 对该数据做了修改。如果 T2 再次读取这个数据,此时读取的结果和第一次读取的结果不同。具体来讲就是,当前事务先进行了一次数据读取,然后再次读取到的数据是别的事务修改成功的数据,导致两次读取到的数据不匹配。
(3)幻影读
T1 读取某个范围的数据,T2 在这个范围内插入新的数据,T1 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。或者用更通俗地说,事务A首先根据条件索引得到N条数据,然后事务B改变了这N条数据之外的M条或者增添了M条符合事务A搜索条件的数据,导致事务A再次搜索发现有N+M条数据了,就产生了幻读。换句话说,当前事务读第一次取到的数据比后来读取到数据条目少。
3、封锁
(1)封锁粒度
MySQL 中提供了两种封锁粒度:行级锁以及表级锁。应该尽量只锁定需要修改的那部分数据,而不是所有的资源。锁定的数据量越少,发生锁争用的可能就越小,系统的并发程度就越高。但是加锁需要消耗资源,锁的各种操作(包括获取锁、释放锁、以及检查锁状态)都会增加系统开销。因此封锁粒度越小,系统开销就越大。在选择封锁粒度时,需要在锁开销和并发程度之间做一个权衡。
(2)封锁类型
A.读写锁
排它锁简写为 X 锁,又称写锁;共享锁简写为 S 锁,又称读锁。有以下两个规定:一个事务对数据对象 A 加了 X 锁,就可以对 A 进行读取和更新。加锁期间其它事务不能对 A 加任何锁。一个事务对数据对象 A 加了 S 锁,可以对 A 进行读取操作,但是不能进行更新操作。加锁期间其它事务能对 A 加 S 锁,但是不能加 X 锁。
B. 意向锁
使用意向锁(Intention Locks)可以更容易地支持多粒度封锁。在存在行级锁和表级锁的情况下,事务 T 想要对表 A 加 X 锁,就需要先检测是否有其它事务对表 A 或者表 A 中的任意一行加了锁,那么就需要对表 A 的每一行都检测一次,这是非常耗时的。意向锁在原来的 X/S 锁之上引入了 IX/IS,IX/IS 都是表锁,用来表示一个事务想要在表中的某个数据行上加 X 锁或 S 锁。有以下两个规定:一个事务在获得某个数据行对象的 S 锁之前,必须先获得表的 IS 锁或者更强的锁;一个事务在获得某个数据行对象的 X 锁之前,必须先获得表的 IX 锁。
(3)封锁协议
封锁协议分为三级封锁协议和两段锁协议。MySQL 的 InnoDB 存储引擎采用两段锁协议,会根据隔离级别在需要的时候自动加锁,并且所有的锁都是在同一时刻被释放,这被称为隐式锁定。InnoDB 也可以使用特定的语句进行显示锁定:
SELECT ... LOCK In SHARE MODE;SELECT ... FOR UPDATE;
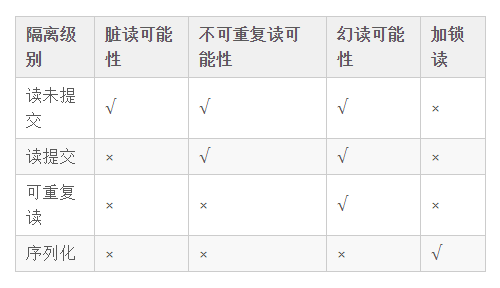
4、隔离级别
为了避免丢失更新、脏读、不可重复读和幻读,在标准SQL规范中,定义了4个事务隔离级别,不同的隔离级别对事务的处理不同。具体如下图:
5、多版本并发控制
多版本并发控制是MySQL的InnoDB存储引擎实现隔离级别的一种具体方式,用于实现提交读和可重复读这两种隔离级别。而未提交读隔离级别总是读取最新的数据行,无需使用 MVCC。可串行化隔离级别需要对所有读取的行都加锁,单纯使用MVCC无法实现。MVCC在大多数情况下代替了行锁。最早的数据库系统,只有读读之间可以并发,读写,写读,写写都要阻塞。引入多版本之后,只有写写之间相互阻塞,其他三种操作都可以并行,这样大幅度提高了InnoDB的并发度。但是,使用MVCC每行记录都需要额外的存储空间,需要做更多的行维护和检查工作。
6、Next-Key Lock
(1)Record Lock
锁定一个记录上的索引,而不是记录本身。如果表没有设置索引,InnoDB 会自动在主键上创建隐藏的聚簇索引,因此 Record Lock 依然可以使用。
(2)Gap Locks
锁定索引之间的间隙,但是不包含索引本身。例如当一个事务执行以下语句,其它事务就不能在 t.c 中插入 15。
SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;
(3)Next-Key Lock
它是 Record Lock 和 Gap Lock 的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙。例如一个索引包含以下值:10, 11, 13, and 20,那么就需要锁定以下区间:
(negative infinity, 10](10, 11](11, 13](13, 20](20, positive infinity)
以上就是数据库原理知识点的全面讲解,大家有任何问题都可以在博学谷官网反映,在线老师将抽时间为大家全力解答~如果本文对大家有帮助,不妨把文章分享出去,让更多的人看到!
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
2020年云计算大数据课程学习大纲
下一篇:
大数据培训班实战项目介绍
相关推荐 更多

科普Spark,什么是Spark?
Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
8574
2019-07-09 12:04:57

Kylin开发教程 从原理讲解到实践演练
众所周知,Kylin是一个可扩展的超快OLAP引擎,它能够提供Hadoop ANSI SQL借口和交互式查询,还可以和BI工具无缝整合,为百亿用户构建立方体。既然学习Kylin这么有必要,那么我们该如何学习它呢?这里为大家介绍博学谷的Kylin开发教程,本教程将会对Kylin进行系统化梳理,包括了Kylin的技术架构、运维不熟、增量构建、实时构建、性能优化等内容,带领大家从原理讲解到实战演练。
5163
2019-11-25 12:22:09

数据仓库和数据挖掘的有什么联系和区别?
数据仓库和数据挖掘的有什么联系和区别?首先我们要清楚数据仓库是一个实现数据存放庞大的地方,而数据挖掘是从海量的数据中提取数据。因此这两者在本质上就存在明显的区别,不过两者既相互区别又相互联系,数据仓库和数据挖掘都可以看做是商业智能工具集合。下面我们来好好认识一下数据仓库和数据挖掘的定义、联系和区别吧!
8844
2020-01-12 17:13:04

大数据开发工程师需要学习哪些知识点?
大数据开发工程师需要学习哪些知识点?大数据程序员需要有坚实的大数据技术理论基础、了解数据平台、掌握数据存储 HDFS、、日志解析及计算 MR、数据获取和预处理 Flume、结构化查询 Hive、数据获取和预处理 Sqoop、大数据调度框架Azkaban、Scala编程基础等相关知识。
6406
2020-09-03 14:13:34

累加器和广播变量分别在什么场景使用?
累加器和广播变量分别在什么场景使用?累加器分布式共享只写变量,如果在转换算子中调用累加器后续没有行动算子,累加器不会执行。后续如果调用了两次行动算子,会执行两次累加器出现多加的情况。
3118
2022-04-19 15:57:48



