在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
什么是数据科学异常值检测原理?异常值的检测方法有基于统计的方法,基于聚类的方法,以及一些专门检测异常值的方法等。使用pandas,可以直接使用describe()来观察数据的统计性描述,或者简单使用散点图也能很清晰的观察到异常值的存在。

一、数据科学异常值检测前提
数据样本符合标准正态分布,正态分布的核心是中心极限定理即:如果一个事物受到多种因素的影响,不管每个因素本身是什么分布,它们加总后,结果的平均值就是正态分布。如果要符合正态分布则这些因素必须彼此独立,彼此不独立的各项因素会互相加强影响,那么就构不成正态分布。
二、数据科学异常值检测原理
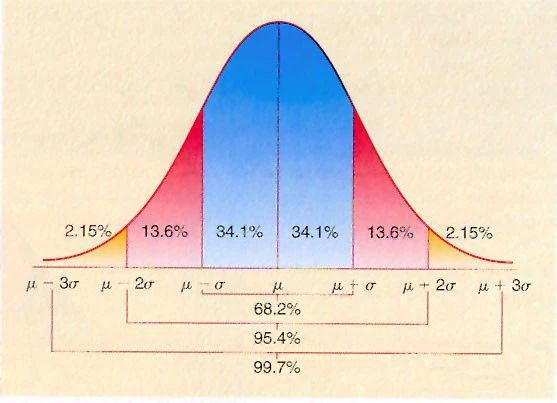
标准正态分布下的曲线为钟型曲线,期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。因此对于一组数据,如果符合正态分布,则可以通过经验法则来检测异常值,同图中可以发现,68.2%的测量值落在μ值处正负一个标准差σ的区间内,95.4%的测量值将落在μ值处正负两个标准差σ的区间内,99.7%的值落在μ值处正负三个标准差σ的区间内。因此,对于一组符合正态分布的数据,如果某个值距离μ值超过三个标准差σ则可以判断这个值属于异常数据。
三、计算步骤
μ值:μ是遵从正态分布的随机变量的均值,由于前提是各种因素对结果的影响为相加,因此μ值的计算可以为样本数据的算术平均值。
标准差σ:所有数据减去其平均值的平方和,所得结果除以该组数之个数N(数据集为总体数据情况,一般用于大数据算法)或者个数N减1(数据集为样本数据情况,认为数据集不是总体数据而是总体数据的一部分,一般用于统计学),再把所得值开根号,所得之数就是这组数据的标准差。
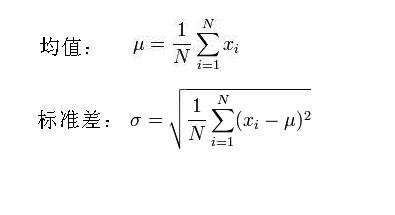 判断逻辑:计算μ+3σ,μ-3σ,当单个数据大于μ+3σ或者小于μ-3σ时,认为此数据为异常值,因为按照经验法则,此数据在数据集的99.7%范围外。
判断逻辑:计算μ+3σ,μ-3σ,当单个数据大于μ+3σ或者小于μ-3σ时,认为此数据为异常值,因为按照经验法则,此数据在数据集的99.7%范围外。
首先理解数据科学异常值检测原理,掌握计算步骤,最终实现对数据科学异常值检测。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
机器学习和数据科学工程师的区别是什么?
下一篇:
常见的数据建模工具有哪些?
相关推荐 更多

大数据是什么?有什么巨大价值?
随着市场经济的不断发展以及互联网科技的快速提升,信息流通的价值也越来越大,马云曾指出我们即将进入DT的时代。因此大数据成为炙手可热的关键因素。大数据更像是矿藏,不只是因为他的量大,而更在于这些数据背后所带来的的价值以及利益。那大数据到底是什么?他的背后隐含着什么样的巨大价值呢?
7633
2019-08-09 18:04:03

学大数据技术必须了解的大数据经典应用案例
我们已经进入了数据化的时代,大数据开发技术、数据分析已经成为目前企业最核心的关注点。数据为企业提供了更加可靠的支撑,对于优化产业结构、提升生产效率有非常明显的作用。在企业纷纷布局大数据业务的同时,大数据相关人才缺口逐渐扩大。目前国内大数据相关从业人员已经超过20万,作为大数据从业人员,必须了解一些大数据相关的经典应用案例。
6326
2019-08-22 18:03:14
HDFS基本原理总结
今天继续梳理的知识点是HDFS的基本原理,主要内容包括NameNode概述、DataNode概述、HDFS的工作机制(HDFS写数据流程和HDFS读数据流程),总之全文都是总结的学习干货,希望对于相信大数据的朋友能够有一些帮助,下面我们一起来学习并理解以下的内容吧!
5013
2020-06-15 10:48:02

大数据开发为什么要参加系统学习呢?
自从发展大数据产业被写入政府工作报告、BAT高薪聘请专业大数据人才之后,很多小白也开始纷纷转行进入大数据领域。很多的转型者都将参加培训机构看成是自己转型最高效的方式。
3710
2020-12-10 15:31:43
Spark SQL 结构化数据处理流程及原理是什么?
Spark SQL 可以使用现有的 Hive 元存储、SerDes 和 UDF。它可以使用 JDBC/ODBC 连接到现有的 BI 工具。有了 Spark SQL,用户可以编写 SQL 风格的查询。
3044
2022-05-25 11:35:20



