在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
SparkSQL 结构化数据处理流程及原理是什么?Spark SQL 可以使用现有的Hive元存储、SerDes 和 UDF。它可以使用 JDBC/ODBC 连接到现有的 BI 工具。有了 Spark SQL,用户可以编写 SQL 风格的查询。
Spark SQL 是 Spark 生态系统中处理结构化格式数据的模块。它在内部使用 Spark Core API 进行处理,但对用户的使用进行了抽象。这篇文章深入浅出地告诉你 Spark SQL 3.x 的新内容。
这对于精通结构化查询语言或 SQL 的广大用户群体来说,基本上是很有帮助的。用户也将能够在结构化数据上编写交互式和临时性的查询。Spark SQL 弥补了弹性分布式数据集RDD和关系表之间的差距。RDD 是 Spark 的基本数据结构。它将数据作为分布式对象存储在适合并行处理的节点集群中。RDD 很适合底层处理,但在运行时很难调试,程序员不能自动推断模式schema。另外,RDD 没有内置的优化功能。Spark SQL 提供了数据帧DataFrame和数据集来解决这些问题。
Spark SQL 可以使用现有的 Hive 元存储、SerDes 和 UDF。它可以使用 JDBC/ODBC 连接到现有的 BI 工具。
数据源
大数据处理通常需要处理不同的文件类型和数据源(关系型和非关系型)的能力。Spark SQL 支持一个统一的数据帧接口来处理不同类型的源,如下所示。
文件:
CSV
Text
JSON
XML
JDBC/ODBC:
Postgres
带模式的文件:
AVRO
Parquet
Hive 表:
Spark SQL 也支持读写存储在 Apache Hive 中的数据。
通过数据帧,用户可以无缝地读取这些多样化的数据源,并对其进行转换/连接。
Spark SQL 3.x 的新内容
在以前的版本中(Spark 2.x),查询计划是基于启发式规则和成本估算的。从解析到逻辑和物理查询计划,最后到优化的过程是连续的。这些版本对转换和行动的运行时特性几乎没有可见性。因此,由于以下原因,查询计划是次优的:
1、缺失和过时的统计数据
2、次优的启发式方法
3、错误的成本估计
Spark 3.x 通过使用运行时数据来迭代改进查询计划和优化,增强了这个过程。前一阶段的运行时统计数据被用来优化后续阶段的查询计划。这里有一个反馈回路,有助于重新规划和重新优化执行计划。
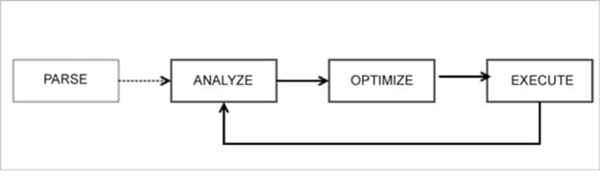
自适应查询执行(AQE)
查询被改变为逻辑计划,最后变成物理计划。这里的概念是“重新优化”。它利用前一阶段的可用数据,为后续阶段重新优化。正因为如此,整个查询的执行要快得多。
动态合并“洗牌”分区
Spark 在“洗牌shuffle”操作后确定最佳的分区数量。在 AQE 中,Spark 使用默认的分区数,即 200 个。这可以通过配置来启用。
动态切换连接策略
广播哈希是最好的连接操作。如果其中一个数据集很小,Spark 可以动态地切换到广播连接,而不是在网络上“洗牌”大量的数据。
动态优化倾斜连接
如果数据分布不均匀,数据会出现倾斜,会有一些大的分区。这些分区占用了大量的时间。Spark 3.x 通过将大分区分割成多个小分区来进行优化。
其他改进措施
此外,Spark SQL 3.x还支持以下内容。
动态分区修剪
3.x 将只读取基于其中一个表的值的相关分区。这消除了解析大表的需要。
连接提示
如果用户对数据有了解,这允许用户指定要使用的连接策略。这增强了查询的执行过程。
兼容 ANSI SQL
在兼容 Hive 的早期版本的 Spark 中,我们可以在查询中使用某些关键词,这样做是完全可行的。然而,这在 Spark SQL 3 中是不允许的,因为它有完整的 ANSI SQL 支持。例如,“将字符串转换为整数”会在运行时产生异常。它还支持保留关键字。
较新的 Hadoop、Java 和 Scala 版本
从 Spark 3.0 开始,支持 Java 11 和 Scala 2.12。 Java 11 具有更好的原生协调和垃圾校正,从而带来更好的性能。 Scala 2.12 利用了 Java 8 的新特性,优于 2.11。
Spark 3.x 提供了这些现成的有用功能,而无需开发人员操心。这将显着提高 Spark 的整体性能。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
大数据在医疗领域应用有哪些挑战?
下一篇:
如何成为高薪的复合型大数据人才?
相关推荐 更多

物联网怎么保护云计算安全?
全球应用的物联网设备已经达到数十亿台,且数量不断增加。在开发和部署的许多物联网设备却缺乏关键的安全功能为黑客和僵尸网络的目标。没有适当的安全措施,物联网设备会导致灾难性事件。如何解决这些问题呢?
4637
2020-03-23 17:51:20

大数据开发工程师需要学习哪些知识点?
大数据开发工程师需要学习哪些知识点?大数据程序员需要有坚实的大数据技术理论基础、了解数据平台、掌握数据存储 HDFS、、日志解析及计算 MR、数据获取和预处理 Flume、结构化查询 Hive、数据获取和预处理 Sqoop、大数据调度框架Azkaban、Scala编程基础等相关知识。
6395
2020-09-03 14:13:34

跳槽直接涨薪25k年薪60w 羡慕的话说麻了
“羡慕”这个词我真的说麻了,之前的薪资25k就已经很高了但是在学完《狂野大数据》课程后找工作直接薪资翻倍
2647
2022-06-07 14:06:39

工信部测算到2025年中国大数据产业规模将突破3万亿元
工信部测算到2025年中国大数据产业规模将突破3万亿元,全球互联网、大数据、云计算、数字孪生、元宇宙等数字技术加速创新趋势,探讨数字科技革命和产业变革的新机遇,聚焦大数据与实体经济、社会治理、民生服务、乡村振兴的深度融合,发布一批大数据创新应用场景,探讨共享应用场景创新的价值。
2629
2022-06-09 15:29:53

传智教育博学谷狂野大数据课程再传喜讯,学员均薪超2万
近日,传智教育旗下博学谷IT在线教育公开了一组大数据学科的就业薪资数据,即全部学员平均就业薪资为 21775元,平均涨薪额度为8229元,涨幅64.00%;其中,一线城市平均就业薪资24274元,一线城市平均涨薪额度为10080元,涨幅76.91%。
2785
2022-09-29 16:42:09



