在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
分析Nginx访问日志需要学什么?需要掌握Spark SQL核心知识,分析Nginx访问日志掌握SparkSQL数据分析能力,SparkSQL调优方式及其核心思想。通过思维导图的方式对学习课程所涉及的知识。

1、Spark SQL介绍
Spark SQL在Spark生态圈的地位和作用,让大家对Spark SQL 的总体知识框架有个大概的轮廓。
2、认识Spark SQL
Spark SQL运行原理,DataFrame、DataSet和RDD的相互转化和使用场景,并讲解Parquet的使用。
2.1 Spark SQL和Hive
2.2 Spark SQL运行原理
2.3 DataFrame、DataSet和RDD的联系
2.4 Parquet列式存储
3、 DataFrame/DataSet常用操作
DataFrame的过滤,分组,排序操作和列值的增删改,以及对Join的优化。
3.1 一般操作:查找和过滤
3.2 聚合操作:groupBy和agg
3.3 单表操作:列的增删改与空值处理
3.4 多表操作:join
4、自定义函数和开窗函数
讲解自定义函数的使用,以及开窗函数在分组求TopN中的应用。
4.1 自定义函数:UDF
4.2 自定义聚合函数:UDAF
4.3 开窗函数:row_number()
5、Nginx访问日志分析完整实战
使用Spark SQL分析Nginx访问日志的项目。包括了数据清洗,存储,监控和优化。
5.1 项目场景介绍及分析
5.2 第一次数据清洗:格式化原始日志数据
5.3 第二次数据清洗:解析数据并按天以Parquet格式存储
5.4 将分析结果批量写入MySql
5.5 性能监控及优化
日志服务查询分析能力是完整SQL92,支持各种数理统计与计算。目前,日志服务支持保存查询语句为快速查询,对查询设置触发周期(间隔),并对执行结果设定判断条件并且告警。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
2020年大数据技术发展趋势如何?
下一篇:
2020年大数据发展前景如何?
相关推荐 更多

你那么努力为什么还又穷又忙?数据分析直播课预告
如果说:“有什么事比穷更可怕?”那一定是“又穷又忙!”加班熬夜写方案,优化产品,留存率却不见提升;公众号文章不断优化,新增用户也是寥寥无几;社群不停维护,优惠不断增加,用户依然不买账;……
5454
2019-08-21 15:55:07
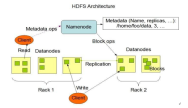
HDFS基本原理总结
今天继续梳理的知识点是HDFS的基本原理,主要内容包括NameNode概述、DataNode概述、HDFS的工作机制(HDFS写数据流程和HDFS读数据流程),总之全文都是总结的学习干货,希望对于相信大数据的朋友能够有一些帮助,下面我们一起来学习并理解以下的内容吧!
5004
2020-06-15 10:48:02

大数据分析的方法有几种?
大数据分析的方法有几种?大数据分析六种方法:数字和趋势、维度分解、用户分群、转化漏斗、行为轨迹、留存分析。看数字及趋势是最基础进行展示相关数据管理信息的方法,对于谁符合一定的行为或背景资料,分类处理用户。
5026
2020-07-22 15:59:31

数据预处理的方法有哪些?
数据处理的工作时间占据了整个数据分析项目的70%以上。因此,数据的质量直接决定了分析模型的准确性。那么,数据预处理的方法有哪些呢?比如数据清洗、数据集成、数据规约、数据变换等,其中最常用到的是数据清洗与数据集成,下面小编将来详细介绍一下这2种方法。
9896
2020-08-11 10:14:41

Hadoop 狂野大数据课件学习内容有哪些?
Hadoop 狂野大数据课件学习内容有哪些?课程学习从Hadoop基本使用、运行原理、实战案例全方位讲解;从概念讲起,课程内容精炼学习效率高没有接触过Hadoop的学员也能很好理解。
2443
2022-06-14 11:09:46



