在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
本文就Hive数据仓库层级划分进行详细介绍,全文大概分为数据仓库的四个操作和四逻辑架构层次两个部分。这些都是Hive数据仓库的基础知识,大家一定要掌握哦!
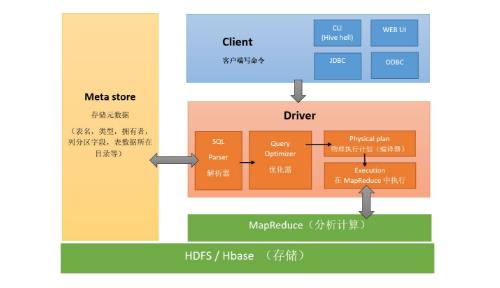
1.数据仓库的四个操作
ETL(extractiontransformation loading)负责将分散的、异构数据源中的数据抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中。ETL 是实施数据仓库的核心和灵魂,ETL规则的设计和实施约占整个数据仓库搭建工作量的 60%~80%.
(1)数据抽取(extraction)包括初始化数据装载和数据刷新:初始化数据装载主要关注的是如何建立维表、事实表,并把相应的数据放到这些数据表中;而数据刷新关注的是当源数据发生变化时如何对数据仓库中的相应数据进行追加和更新等维护(比如可以创建定时任务,或者触发器的形式进行数据的定时刷新)。
(2)数据清洗主要是针对源数据库中出现的二义性、重复、不完整、违反业务或逻辑规则等问题的数据进行统一的处理。即清洗掉不符合业务或者没用的的数据。比如通过编写hive或者MR清洗字段中长度不符合要求的数据。
(3)数据转换(transformation)主要是为了将数据清洗后的数据转换成数据仓库所需要的数据:来源于不同源系统的同一数据字段的数据字典或者数据格式可能不一样(比如A表中叫id,B表中叫ids),在数据仓库中需要给它们提供统一的数据字典和格式,对数据内容进行归一化;另一方面,数据仓库所需要的某些字段的内容可能是源系统所不具备的,而是需要根据源系统中多个字段的内容共同确定。
(4)数据加载(loading)是将最后上面处理完的数据导入到对应的存储空间里(mysql等)以方便给数据集市提供,进而可视化。一般大公司为了数据
安全和操作方便,都是自己封装的数据平台和任务调度平台,底层封装了大数据集群比如hadoop集群,spark集群,sqoop,hive,zookeepr,hbase等只提供web界面,并且对于不同员工加以不同权限,然后对集群进行不同的操作和调用。以数据仓库为例,将数据仓库分为逻辑上的几个层次。这样对于不同层次的数据操作,创建不同层次的任务,可以放到不同层次的任务流中进行执行(大公司一个集群通常每天的定时任务有几千个等待执行,甚至上万个,所以划分不同层次的任务流,不同层次的任务放到对应的任务流中进行执行,会更加方便管理和维护)。
2.数据仓库的四个逻辑架构层次
数据仓库标准上可以分为四层。但是注意这种划分和命名不是唯一的,一般数仓都是四层,但是不同公司可能叫法不同。比如这里的临时层叫复制层SSA,京东则叫BDM。同样阿里巴巴却是五层数仓结构,更加详细,但是核心的理念都是从四层数据模型而来。
(1)复制层(SSA,system-of-records-staging-area)
SSA 直接复制源系统(比如从mysql中读取所有数据导入到hive中的同结构表中,不做处理)的数据,尽量保持业务数据的原貌;与源系统数据唯一不同的是,SSA 中的数据在源系统数据的基础上加入了时间戳的信息,形成了多个版本的历史数据信息。
(2)原子层(SOR,system-of-record)
SOR 是基于模型开发的一套符合 3NF 范式规则的表结构,它存储了数据仓库内最细层次的数据,并按照不同的主题域对数据分类存储;比如高校数据统计服务平台根据目前部分需求将全校数据在 SOR 层中按人事、学生、教学、科研四大主题存储;SOR 是整个数据仓库的核心和基础,在设计过程中应具有足够的灵活性,以能应对添加更多的数据源、支持更多的分析需求,同时能够支持进一步的升级和更新.
(3)汇总层(SMA,summary-area)
SMA 是 SOR和DM(集市层) 的中间过渡,由于 SOR 是高度规范化数据,此要完成一个查询需要大量的关联工作,同时DM 中的数据粒度往往要比 SOR 高很多,对要生DM 中的汇总数据需要进行大量的汇总工作,此,SMA 根据需求把 SOR 数据进行适度的反范(例如,设计宽表结构将人员信息、干部信息等多表的数据合并起来)和汇总(例如,一些常用的头汇总、机构汇总等);从而提高数据仓库查询性能。
(4)集市层/展现层(DM, data mart)
DM 保存的数据供用户直接访问的:可以将 DM 理解成最终用户接最终想要看的数据;DM 主要是各类粒度的事数据,通过提供不同粒度的数据,适应不同的数访问需求;高校数据统计服务平台 DM 中的数据。
以上就是Hive数据仓库层级划分介绍,大家都记住了吗?
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
大数据时代带给我们的重大变革
下一篇:
数据分析对企业经营的作用和现实意义
相关推荐 更多
大数据分析是什么?大数据分析有什么好处?
大数据是目前互联网市场极其火爆的词汇,其商业价值的利用也成为目前互联网企业关注的焦点。随着大数据时代的快速发展,大数据分析也应用而生,大数据分析是什么?大数据分析有什么好处呢?
10071
2019-08-23 18:30:00

大数据技术的应用领域有哪些?
大数据技术逐渐成熟,已经在诸多领域得到了广泛的应用,随着5G时代的带来,数据化的企业运营成为企业优化产业结构、提升服务质量的奠基。在数据时代数据量迅速扩大、数据维度不断完善、数据分析的指导性更加明显。那大数据技术的应用领域有哪些呢?对于学习大数据技术的同学们而言,应该精准到哪些行业就业呢?
16127
2019-12-16 18:57:00

零基础学大数据难吗?
零基础学大数据难吗?通过各大招聘平台我们可以看到,同样都是互联网技术岗位,大数据技术岗位的薪资普遍较高,不仅仅是因为目前布局大数据技术是各个企业的战略目标,同时也因为大数据技术有一定的难度,那对于零基础的同学能学会大数据技术吗?
5359
2020-08-24 14:31:50

学习大数据前应该了解什么?
大数据学习不能停留在理论的层面上,大数据方向切入应是全方位的,基础语言的学习只是很小的一个方面,编程落实到最后到编程思想。学习前一定要对大数据有一个整体的认识。
3788
2021-01-06 10:19:34

Sequence File格式是什么?如何使用?
Hadoop可以存储多种文件格式。sequenceFile文件是Hadoop用来存储二进制形式的[Key,Value]对而设计的一种平面文件(Flat File)。可以把SequenceFile当做是一个容器,把所有的文件打包到SequenceFile类中可以高效的对小文件进行存储和处理。
5656
2021-03-16 13:59:21



