在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
Spark与Hadoop大数据计算框架区别是什么?ApacheSpark专为大规模数据处理而设计的快速通用的计算引擎,而Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop和Spark都是大数据框架,但各自存在的目的不同。Hadoop实质上是一个分布式数据基础设施,将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,也有计算处理功能。Spark是一个专门用来对那些分布式存储的大数据进行处理的工具并不会进行分布式数据的存储。

Spark是什么?
Spark是一种通用的大数据计算框架,正如传统大数据技术Hadoop的MapReduce、Hive引擎,以及Storm流式实时计算引擎等。Spark包含大数据领域常见的各种计算框架:如SparkCore用于离线计算,SparkSQL用于交互式查询,SparkStreaming用于实时流式计算,SparkMLlib用于机器学习,SparkGraphX用于图计算。
Spark主要用于大数据的计算,而Hadoop以后主要用于大数据的存储(比如HDFS、Hive、HBase等),以及资源调度(Yarn)。
Hadoop是什么?
Hadoop是项目总称,由HDFS和MapReduce组成。HDFS是GoogleFileSystem(GFS)的开源实现。MapReduce是GoogleMapReduce的开源实现。ApacheHadoop软件库是一个允许使用简单编程模型跨计算机集群处理大型数据集合的框架,其设计的初衷是将单个服务器扩展成上千个机器组成的一个集群为大数据提供计算服务,其中每个机器都提供本地计算和存储服务。
Hadoop与Spark都是大数据计算框架,但两者各有自己的优势,那么Spark与Hadoop的区别如下:
1、编程方式
Hadoop的MapReduce在计算数据时,计算过程必须要转化为Map和Reduce两个过程,从而难以描述复杂的数据处理过程;而Spark的计算模型不局限于Map和Reduce操作,还提供了多种数据集的操作类型,编程模型比MapReduce更加灵活。
2、数据存储
Hadoop的MapReduce进行计算时,每次产生的中间结果都是存储在本地磁盘中;而Spark在计算时产生的中间结果存储在内存中。
3、数据处理
Hadoop在每次执行数据处理时,都需要从磁盘中加载数据,导致磁盘的I/O开销较大;而Spark在执行数据处理时,只需要将数据加载到内存中,之后直接在内存中加载中间结果数据集即可,减少了磁盘的1O开销。
4、数据容错
MapReduce计算的中间结果数据保存在磁盘中,且Hadoop框架底层实现了备份机制,从而保证了数据容错;同样SparkRDD实现了基于Lineage的容错机制和设置检查点的容错机制,弥补了数据在内存处理时断电丢失的问题。在Spark与Hadoop的性能对比中,较为明显的缺陷是Hadoop中的MapReduce计算延迟较高,无法胜任当下爆发式的数据增长所要求的实时、快速计算的需求。
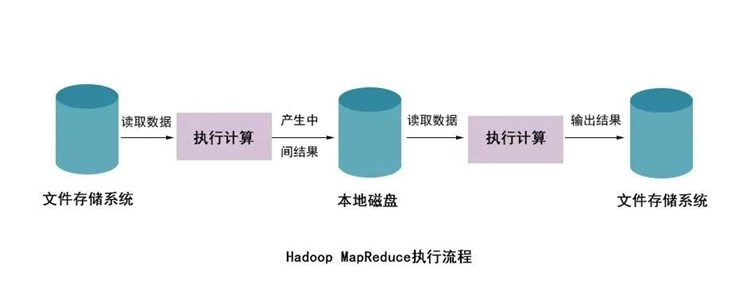
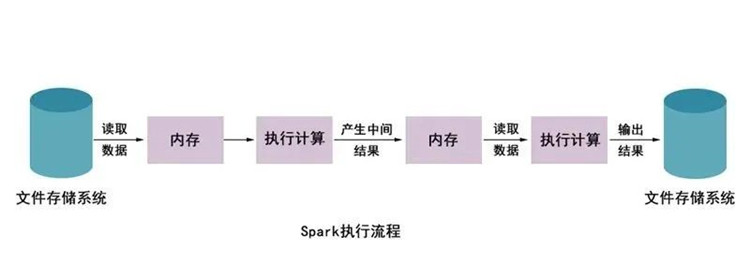
使用HadoopMapReduce进行计算时,每次计算产生的中间结果都需要从磁盘中读取并写入,大大增加了磁盘的I/O开销,而使用Spark进行计算时,需要先将磁盘中的数据读取到内存中,产生的数据不再写入磁盘,直接在内存中迭代处理,这样就避免了从磁盘中频繁读取数据造成的不必要开销。
Spark是一种与Hadoop相似的开源集群计算环境,不同之处使Spark在某些工作负载方面表现得更加优越,Spark启用了内存分布数据集,除了能够提供交互式查询外还可以优化迭代工作负载。Spark是在Scala语言中实现,将Scala用作其应用程序框架。与Hadoop不同Spark和Scala能够紧密集成,其中的Scala可以像操作本地集合对象一样轻松地操作分布式数据集。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
常见数据分析误区有哪些?你犯了吗?
下一篇:
大数据开发培训哪家好?怎么选?
相关推荐 更多

大数据Lambda架构概念及应用
Lambda Architecture 概念Mathan Marz的大作Big Data: Principles and best practices of scalable real-time data systems介绍了Lambda Architecture的概念,用于在大数据架构中,如何让real-time与batch job更好地结合起来,以达成对大数据的实时处理。
9203
2020-09-04 17:57:48
大数据面试题之分布式资源调度框架Yarn
Yarn作为一个资源管理、任务调度的框架,其重要性不言而喻。尤其是在近些年的大数据面试中,更是面试题的重点知识之一。为了大家在面试的时候,能够准备的更加充分,小编整理了一份有关分布式资源调度框架Yarn的大数据面试题,内容包括Yarn的架构、工作流程、调度器Scheduler。
7567
2019-09-12 11:00:53

掌握Hive架构需要学什么?
Hive是建立在Hadoop上的数据仓库基础构架,它提供了一系列的工具,可以用来进行数据提取转化加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类 SQL 查询语言,它允许熟悉SQL的用户查询数据。因此掌握Hive是学习大数据的必修课,那么掌握Hive架构需要学什么呢?本文将为大家讲述Hive的具体学习内容,下面是Hive视频教程的学习大纲:
5030
2020-05-11 18:05:41
大数据开发离线计算框架知识点总结
大数据开发离线计算框架知识点总结,大数据在带来发展机遇的同时,也带来了新的挑战,催生了新技术的发展和旧技术的革新。大数据离线计算技术应用于静态数据的离线计算和处理,框架设计的初衷是为了解决大规模、非实时数据计算,更加关注整个计算框架的吞吐量。
6069
2020-07-16 16:41:14

Spark SQL架构工作原理及流程解析
spark sql从shark发展而来,Shark为了实现Hive兼容,在HQL方面重用了Hive中HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑。
4987
2021-05-18 10:53:42



