在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
Logstash开发采集上亿级别数据,需求属于日志采集的范畴,Logstash本身不支持反序列化功能,需要自定义开发ruby插件来支持,使用MLSQL结合UDF的方式进行流式处理。MLSQL写入hdfs会产生大量的小文件,需要单独开发合并文件的功能,写入es的数据是需要数仓结合其他业务数据进行建模,用离线处理的方式。
开发背景:公司业务系统做优化改造,同时为了能够实现全链路监控需收集所有业务系统之间的调用日志;数据情况:每天20亿以上;机器成本:3台kafka集群;2台logstash采集机器;技术:Java,MQ,MLSQL,Logstash。
采集流程:
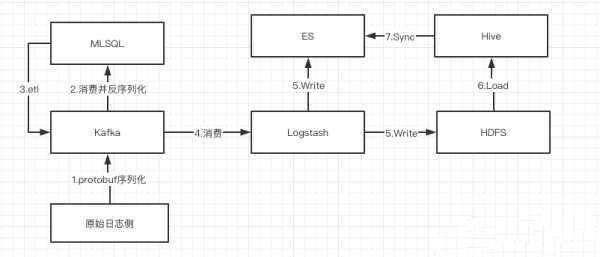
MLSQL 消费MQ:原始日志产生侧通过protobuf进行序列化推送至mq,然后通过MLSQL进行反序列化并进行简单的etl处理后,再推送至MQ;
通过Logstash进行消费MQ:通过logstash消费经过MLSQL处理后的数据,并在这里通过ruby进行再次的加工处理,最后写入es和hdfs(一部分流程推送到es是业务侧使用,而另一部分写入hdfs是提供给数仓使用)
数仓建模:通过数仓建模,将最后的指标结果推送至es提供给业务侧使用,主要是借鉴这个需求讲解Logstash在实际场景中的使用以及优化。
Logstash开发流程:
1、确定日志格式
一个日志文件里肯定是不止一种日志格式,也有可能是标准化的格式,这里需要跟日志产生侧进行确认格式。
2、调试grok
确定好日志格式后,编写grok语法,然后进行调试,本人是通过kibana6自带的grok debug进行调试。结合该需求背景,最后经过logstash采集的时候,其实已经通过MLSQL进行了处理,最后Logstash消费的是格式就是一个json字符串,所以不需要grok语法。
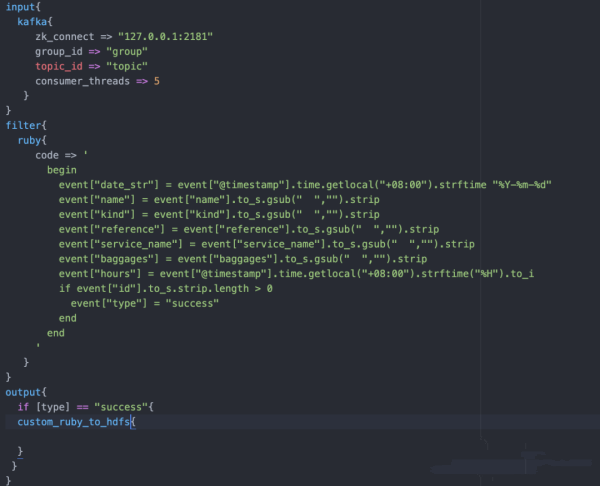
3、调试ruby
结合该需求,使用ruby进行一些清洗逻辑
4、优化
优化工作在整个需求开发周期的比例较大,数据量较大资源较少,具体优化思路如下:
(1)MLSQL优化
这部分的优化工作主要是在反序化这块,剔除一部分无用字段,以及提前过滤一部分数据量,一部分注册UDF的代码:

(2)Kafka端优化
因kafka集群是集团共用,所以kafka端的优化其实只涉及到消费端的优化。这里只调节数据压缩、消费者线程数这两个参数。
(3)hdfs优化
logstash写入hdfs的部分不用使用自带的webhdfs插件,而是自定义的插件。
因自定义插件中涉及到文件锁的问题,会通过比对前后两次文件是否一致来进行文件最后的刷写,所以这里只能通过减少文件的更新频率来减少上下文的切换以及刷写操作
(4)ES优化
es部分的优化也只是涉及到写优化,比如批量写入、调大线程数、增加refresh间隔、禁止swapping交换内存、禁止refresh和replica操作,调大index buffer等操作。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
零基础报Java培训班学4个月有用吗?学习效果如何?
下一篇:
Spring AOP应用场景有哪些?Aop工作原理分析
相关推荐 更多

零基础入门Java从哪里开始?
Java在编程语言中老大哥的地位,一直以来都是无法撼动的!因此Java也往往是许多零基础编程初学者的首选语言,然而对于大多数小白来讲,最困惑的事情莫过于零基础入门Java应该从哪里开始。众所周知,学习最重要的就是要有一个系统的规划,这样才不至于在一开始就走错方向。因此本文为大家整理了一条初学者的入门路线,大家可以先参考以下的这份学习大纲开始学习~
4005
2020-04-27 10:10:46

Zookeeper从入门到实践要学什么?
ZooKeeper是一种分布式协调服务,它用简单的架构和API,解决了在分布式环境中协调和管理服务的难题。那么,Zookeeper从入门到实践要学什么呢?以博学谷相关的免费课程为例,课程主要讲解了包括集群结构、集群配置、常用命令、部署模式、Zab协议、Dubbo架构等重要核心知识,并结合经典售票案例与实际应用。
4404
2020-06-26 18:22:26

Java字节流输入输出数据的常用方法介绍
字节流由字节组成,在计算机中无论是文本、图片、音频还是视频所有文件都是以二进制(字节)形式存在,根据数据的传输方向可将其分为字节输入流和字节输出流。
3871
2021-04-23 13:53:46

MySQL数据库as和distinct关键字怎么用?代码怎么写?
MySQL数据库as和distinct关键字怎么用?代码怎么写?使用SQL语句显示结果时,在屏幕显示的字段名不具备良好的可读性,我们可以使用 as 给字段起一个别名。在很多重复数据想要对其中重复数据行进行去重操作可以使用 distinct。
3260
2022-01-12 16:13:57

MySQL数据库的基本使用之排序查询语法
MySQL数据库的基本使用之排序查询语法,为了方便查看数据可以对数据进行排序。学习排序我们需要掌握升序查询和降序查询的关键字。
3349
2022-01-13 15:42:13



