在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
Hive是建立在Hadoop上的数据仓库基础构架。对于有一定基础的大数据学习者来讲,Hive是必须掌握的核心技术。本文主要带大家来认识一下Hive,了解什么是Hive?为什么要用Hive?如果大家对这些问题好奇,就一起看看接下来的内容吧~

1、什么是Hive?
(1)Hive的定义
Hive一个可以将结构化的数据文件映射为一张数据库表并提供类SQL查询功能的数据仓库工具,而且它是基于Hadoop的。因此,从本质上来看,Hive是将SQL转换为MapReduce程序的工具。因为,比直接用MapReduce开发效率更高,Hive的主要作用就是用来做离线数据分析。
(2)Hive架构
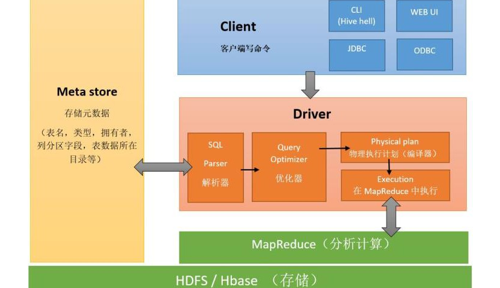
用户接口:包括 CLI 、JDBC/ODBC 、WebGUI 。其中, CLI(command line interface)为 shell 命令行;JDBC/ODBC 是 Hive 的 JAVA 实现,与传统数据库JDBC 类似;WebGUI 是通过浏览器访问 Hive。
元数据存储:通常是存储在关系数据库如 mysql/derby 中。Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS中,并在随后有 MapReduce 调用执行。
(3)Hive数据模型
Hive中所有的数据都存储在HDFS中,没有专门的数据存储格式。在创建表时指定数据中的分隔符,Hive就可以映射成功,解析数据。Hive中包含以下数据模型:
db:在hdfs中表现为hive.metastore.warehouse.dir目录下一个文件夹;
table:在hdfs中表现所属db目录下一个文件夹;
external table:数据存放位置可以在 HDFS 任意指定路径;
partition:在hdfs中表现为table目录下的子目录;
bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件。
2、为什么要用Hive?
(1)Hive与传统数据库对比
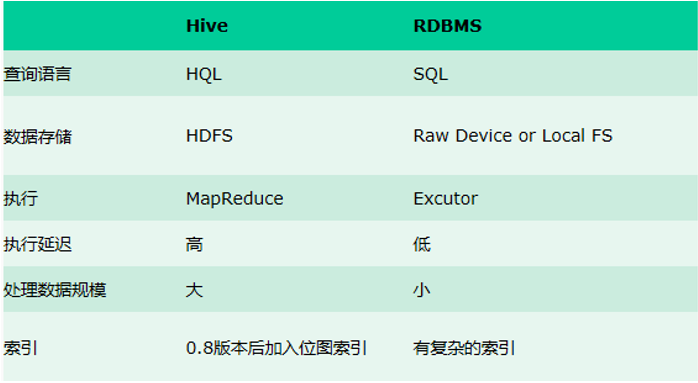
Hive用于海量数据的离线数据分析。Hive具有sql数据库的外表,但应用场景完全不同,Hive只适合用来做批量数据统计分析。
(2)Hive的优势
Hive利用HDFS存储数据,利用MapReduce查询分析数据。因为直接使用Hadoop MapReduce处理数据,会面临人员学习成本太高的问题,而且MapReduce实现复杂查询逻辑开发难度太大。而使用Hive,操作接口采用类SQL语法,提供快速开发的能力的同时还避免了去写MapReduce,从而减少开发人员的学习成本,功能扩展更加方便。
看到这里,想必大家对于“什么是Hive?为什么要用Hive?”,已经有了一定的了解。如果大家想要更加深入的学习大数据中的核心技术Hive,可以在下方申请免费试学名额,获取免费的大数据在线学习机会~
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
什么是数据库?用来做什么?
下一篇:
数据仓库是什么?基本概念讲解
相关推荐 更多

程序员常用数据库有哪些?
数据库就是数据存储的仓库,任何互联网产品都需要使用数据库保存运营过程中所产生的各种数据。SQL是一种数据库查询语言和程序设计语言,主要就是用于管理数据库中的数据,如存取数据、查询数据、更新数据等。在大数据技术不断提升与应用的市场背景下,数据库技术也得到很大的发展,目前数据库产品非常多,最常用的数据库有:Oracle、DB2、MongoDB、SQLServer、MySQL等。
9677
2019-12-05 18:48:08

数据科学与机器学习的区别是什么?
数据科学与机器学习的区别:机器学习是人工智能的一个分支,而数据科学是数据清理、准备和分析的学科。人们需要了解每种技术的工作原理,以及它们是如何一起工作的。数据科学是一种实践领域,而机器学习是一组工具和方法论。
6073
2020-05-13 15:36:30

HDFS垃圾桶机制总结
本文是一篇关于梳理HDFS垃圾桶机制的学习干货总结,主要内容包括垃圾桶机制概述、垃圾桶机制配置、shell操作、Java操作以及圾桶机制验证。下面赶紧来一起看看吧~
4890
2020-06-17 16:33:24

深度学习工程师必须掌握的神经网络架构
深度学习工程师必须掌握的神经网络架构,神经网络架构分为四大类:标准网络、递归网络、卷积网络、自动编码器。神经网络可以用来可视化的数据包含两部分:每一层神经元的输出,它们对应输入数据在网络中的不同表示每个神经元所学习到的权重,刻画着各个神经元的行为,即如何对输入进行响应的。
5876
2020-07-01 17:34:28

如何利用大数据构建用户画像?
大数据时代,不仅普通用户可以享受到技术带来的便利,企业也可以从数据中提取有商业价值的信息,构建出用户画像,从而对用户行为进行分析和预测。虽然用户画像不是什么新鲜的概念,但是大数据技术的出现使得用户画像更加清晰客观。下面我们一起来看看如何利用大数据构建用户画像。
5280
2020-07-23 12:12:02



