在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
作为一名合格的运营,很多时候需要掌握数据分析能力。⽐如你新进到⼀家公司做新媒体内容编辑,那你需要盘点公司已有的内容资产,避免重复⽣产内容。这时候就需要把⽹页上的数据给扒下来,放在⼀起才会⼀⽬了然。从⽹页上爬取数据,最好⽤的⽅法当然是爬⾍⼯具啦~本文将为手把手教大家如何使用Web Scraper爬取数据,帮助运营小白快速上手爬虫工具!

第一步:下载 Web Scraper
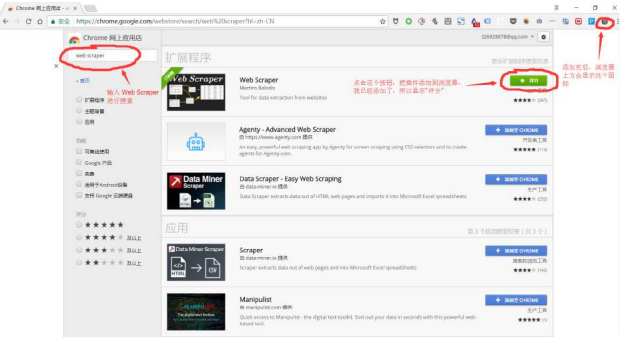
Web Scraper是Chrome浏览器上的⼀个插件,你需要翻墙进⼊Chrome应⽤商店,下载Web Scraper插件。
第二步:打开Web Scraper
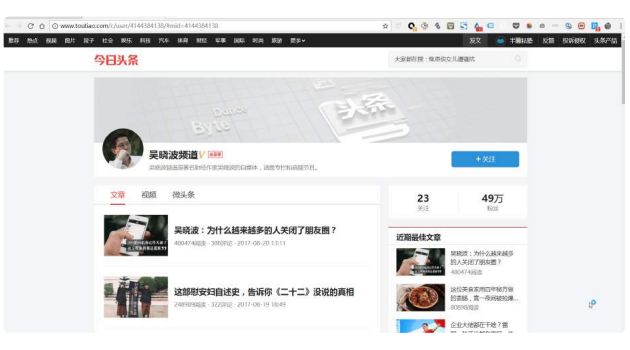
先打开⼀个你想爬数据的⽹页,⽐如我想爬今⽇头条上「吴晓波频道」这个账户的⽂章标题、时间、 评论数,那我就先打开它,再⼀⼀进⾏操作。然后⽤快捷键 Ctrl + Shift + I / F12 打开 Web Scraper。
第三步:新建⼀个 Sitemap
点击Create New Sitemap,⾥⾯有两个选项,import sitemap是指导⼊⼀个现成的sitemap,运营⼩⽩⼀般没有现成的,所以⼀般不选这个,选create sitemap就好。然后进⾏这两个操作:
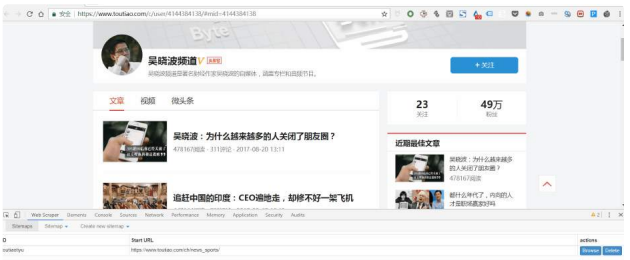
Sitemap Name:代表你这个Sitemap是适⽤于哪⼀个⽹页的,所以你可以根据⽹页来⾃命名,不过需要使⽤英⽂字母,⽐如我抓的是今⽇头条的数据,那我就⽤toutiao来命名;Sitemap URL:把⽹页链接复制到Star URL这⼀栏,⽐如图⽚⾥我把「吴晓波频道」的主页链接复制到了这⼀栏。
第四步:设置这个Sitemap
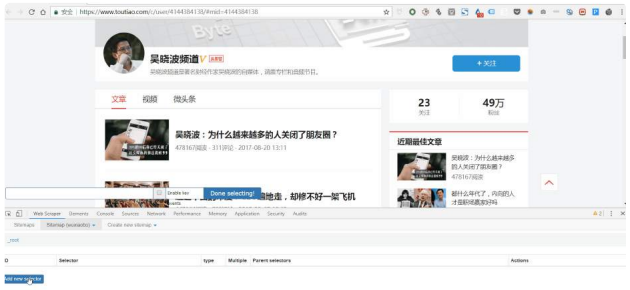
整个Web Scraper的抓取逻辑是这样:设置⼀级Selector,选定定抓取范围;在⼀级Selector 下设置⼆级Selector,选定抓取字段,然后抓取。
再举个例⼦,假如你要获取福建⼈的姓名、性别和年龄这三个要素,那么你得这么做:⾸先要定位到福建省,然后再在福建省⾥⾯去定位姓名、性别、年龄。在这⾥,⼀级Selector表⽰你要在中国这个⼤的国家圈出福建省,⼆级Selector 表⽰你要在福建省的⼈⼜中圈定姓名、性别、年龄这三个要素。对于⽂章⽽⾔,⼀级Selector就是你要把这⼀块⽂章的要素圈出来,这个要素可能包含了标题、作者、发布时间、评论数等等,然后我们再在⼆级Selector 中挑出我们要的要素,⽐如标题、作者、阅读数。
(1)点击Add new selector创建⼀级Selector,按照以下步骤操作:
a.输⼊id : id代表你抓取的整个范围,⽐如这⾥是⽂章,我们可以命名为 126 wuxiaobo-articles;
b.选择 Type : type 代表你抓取的这部分的类型,⽐如元素/⽂本/链接,因为这个是整个⽂章要素范围选取,我们需要⽤Element来先整体选取(如果这个⽹页需要滑动加载更多,那就选Element Scroll Down);
c.勾选Multiple :勾选 Multiple 前⾯的⼩框,因为你要选的是多个元素⽽不是单个元素,当我们勾选的时候,爬⾍插件会帮助我们识别多篇同类的⽂章;
d.保留设置:其余未提及部分保留默认设置。
(2)点击select选择范围,按照以下步骤操作:
a.选择范围:⽤⿏标选择你要爬取数据的范围,绿⾊是待选区域,⽤⿏标点击后变为红⾊,才是选中了这块区域;
b.多选:不要只选⼀个,下⾯的也要选,否则爬出来的数据也只有⼀⾏;
c.完成选择: 记得点Done Selecting;
d.保存:点击Save Selector。
(3)设置好了这个⼀级的Selector之后,点进去设置⼆级的Selector,按照以下步骤操作:
a.新建Selector:点击Add new selector ;
b.输⼊id :id代表你抓取的是哪个字段,所以可以取该字段的英⽂,⽐如我要选「作者」,我就写「writer」;
c.选择Type:选Text ,因为你要抓取的是⽂本;
d.勿勾选Multiple:不要勾选Multiple前⾯的⼩框,因为我们在这⾥要抓取的是单个元素; 保留设置:其余未提及部分保留默认设置。
(4)点击select,再点击你要爬取的字段,按照以下步骤作:
a.选择字段:这⾥爬取的字段是单个的,⽤⿏标点击该字段即可选定,⽐如要爬标题,那就⽤⿏标点击某篇⽂章的标题,当字段所在区域变红即为选中;
c.完成选择:记得点 Done Selecting ;
d.保存:点击 Save Selector 。
(5)重复以上操作,指导选完你想爬去的字段。
第五步:爬取数据
之所以说Web Scraper是运营小白必会的爬⾍⼯具,就是因为只需要设置完所有的Selector,就可以开始爬数据了,怎么样是不是很简单?那么怎么开始爬数据呢?只需要⼀个简单的操作:点击 Scrape ,然后点 Start Scraping , 会弹出⼀个⼩窗,然后⾟勤的⼩爬⾍就开始⼯作了。你会得到⼀个列表,上⾯有你想要的所有数据。
以上就是运营小白必会的爬虫工具使用教程,怎么样,你是不是已经快速上⼿Web Scraper的所有操作过程了?相信即使是不会编程语言的小白,也可以掌握在5分钟之内爬取数据的爬虫工具!
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
流量比较多的五大自媒体平台盘点
下一篇:
老带新营销方式的核心逻辑解析
相关推荐 更多

新手应该如何学习短视频运营?
近几年,短视频的热度可以说是一直只增不减。在当下这个流量日渐获取困难的时代,短视频对于流量的获取可以说是十分的可观。以尤目前最大的短视频平台抖音为例,该平台的日活用户可以到达3.2亿。相信不少人都看到了短视频运营的红利,那么新手应该如何学习短视频运营呢?总的来说,只要做好用户画像,定位目标人群,产出优质的内容,再根据数据反馈不断调整路线,短视频运营也没有那么难!
6768
2020-02-20 10:25:02

用户画像包含哪些方面的内容?
如今,在大数据高速发展的背景下,用户画像在各个领域都得到了广泛的应用。构建一个详实的用户画像,有利于运营人员快速了解用户基本情况,为工作的开展提供指导和帮助。那么,用户画像包含哪些方面的内容?一般来说,大概分为以下几个方面,即用户属性、用户行为、用户消费、风险控制和社交属性。下面我们一起来具体看看吧!
45273
2020-04-08 10:52:08

如何运营新媒体?三招搞定
如今,“新媒体运营”这个词越来越受到关注,也成为一个择业的不错选择。新媒体作为一个系统化的行业,进入门槛低,但是要想在众多竞争对手中杀出重围也是需要专业指导的。那究竟该如何运营才能打造优质的新媒体账号,凸显新媒体的真正价值呢?这里有3个建议给到大家。
4347
2020-05-27 14:15:34

网络与新媒体专业就业前景怎么样?
网络与新媒体专业就业前景怎么样?网络与新媒体就业前景好,社会需求大就业面广,可在各类门户网站、党政部门网站、企事业网站等从事信息采集、撰写、编辑等工作。从事与新媒体相关的网站策划、网络推广以及网站建设与管理等方面的工作。
4564
2020-06-02 15:44:06

网络与新媒体专业学什么?
随着物联网的即将来临,信息传播的深度和广度都在发生质的变化,这种变化也在深刻地影响着现代社会的商业经营模式和信息传播技术,因此网络与新媒体专业应运而生。我们可以发现,近几年新媒体运营人才的需求正在逐年扩大。那么,肯定有人好奇了:网络与新媒体专业学什么呢?简单来讲这个专业就是培养网络营销综合型人才,因此需要学习推广拉新、营销策划及媒介推广等核心知识点。
15224
2020-07-08 10:57:15



