在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
目前,聚类算法被广泛应用于用户画像、广告推荐、新闻推送和图像分割等等。聚类算法是机器学习中一种“数据探索”的分析方法,它帮助我们在大量的数据中探索和发现数据的结构。那么机器学习中的聚类算法有哪几种呢?下面我将为大家一一介绍常见的几种聚类算法,分别是高斯聚类模型、基于密度的聚类算法、凝聚层次聚类和均值漂移算法。
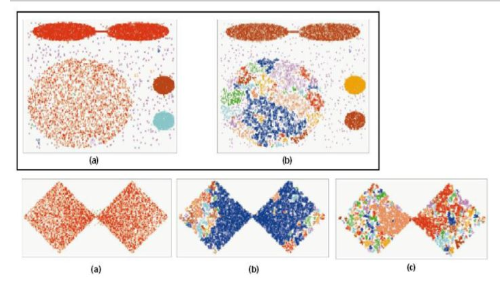
1、高斯聚类模型
事实上,GMM 和 k-means 很像,不过 GMM 是学习出一些概率密度函数来,简单地说,k-means 的结果是每个数据点被 assign 到其中某一个 cluster 了,而 GMM 则给出这些数据点被 assign 到每个 cluster 的概率,又称作 soft assignment 。
2、基于密度的聚类算法
基于密度的聚类算法最大的优点在于无需定义类的数量,其次可以识别出局外点和噪声点、并且可以对任意形状的数据进行聚类。DBSCAN同样是基于密度的聚类算法,但其原理却与均值漂移大不相同:首先从没有被遍历的任一点开始,利用邻域距离epsilon来获取周围点;如果邻域内点的数量满足阈值则此点成为核心点并以此开始新一类的聚类;其邻域内的所有点也属于同一类,将所有的邻域内点以epsilon为半径进行步骤二的计算;重复步骤二、三直到变量完所有核心点的邻域点;此类聚类完成,同时又以任意未遍历点开始步骤一到四直到所有数据点都被处理;最终每个数据点都有自己的归属类别或者属于噪声。
3、K均值聚类
这一最著名的聚类算法主要基于数据点之间的均值和与聚类中心的聚类迭代而成。它主要的优点是十分的高效,由于只需要计算数据点与剧类中心的距离,其计算复杂度只有O(n)。其工作原理主要分为以下四步:首先我们需要预先给定聚类的数目同时随机初始化聚类中心。我们可以初略的观察数据并给出较为准确的聚类数目;每一个数据点通过计算与聚类中心的距离了来分类到最邻近的一类中;根据分类结果,利用分类后的数据点重新计算聚类中心;重复步骤二三直到聚类中心不再变化。
4、凝聚层次聚类
层次聚类法主要有自顶向下和自底向上两种方式。其中自底向上的方式,最初将每个点看做是独立的类别,随后通过一步步的凝聚最后形成独立的一大类,并包含所有的数据点。这会形成一个树形结构,并在这一过程中形成聚类。
5、均值漂移算法
这是一种基于滑动窗口的均值算法,用于寻找数据点中密度最大的区域。其目标是找出每一个类的中心点,并通过计算滑窗内点的均值更新滑窗的中心点。最终消除临近重复值的影响并形成中心点,找到其对应的类别。其工作原理主要是以下几点:首先以随机选取的点为圆心r为半径做一个圆形的滑窗。其目标是找出数据点中密度最高点并作为中心;在每个迭代后滑动窗口的中心将为想着较高密度的方向移动;连续移动,直到任何方向的移动都不能增加滑窗中点的数量,此时滑窗收敛;将上述步骤在多个滑窗上进行以覆盖所有的点。当过个滑窗收敛重叠时,其经过的点将会通过其滑窗聚类为一个类。
以上就是机器学习中常见的五种聚类算法,大家都了解了吗?如果还想深入学习聚类算法的相关内容,比如原理、算法效果的衡量标准以及基于Kmeans算法进行改进的优化方法,可以上博学谷官网进行有关课程的在线学习。希望大家通过课程可以学会使用聚类算法进行数据分析,挖掘商业价值。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
人工智能是什么?人工智能培训的内容是什么?
下一篇:
智能机器人软件开发培训学什么?
相关推荐 更多

AI技术在爱奇艺中的实战应用解析
人工智能时代已经来临了,这不仅仅只是一句口号而已,AI技术的应用早已渗透进我们生活的方方面面。本文将详细为大家解析爱奇艺APP中AI技术的实战应用,像是智能推荐系统利用搜索推荐、深度学习等技术。除此之外,还有一些目前仍在探索中的技术,比如,如何利用人工智能生产对用户量身打造的内容?感兴趣的朋友可以接着看下去。
7253
2019-12-13 16:44:33
在线学习算法难不难?
对程序员来讲,算法可以看作是内功。即使是需要学习许多的招式,但如果没有掌握那些万变不离其宗的的算法和理论,也只是懂得一些花拳绣腿而已,并不能在程序员的道路上走得更远。随着互联网技术和IT培训的发展,越来越多的人选择在线学习算法,来提高自己的专业能力。因此,不免有人也提出来了这样的担忧:在线学习算法难不难?其实只要找到一个优质的课程内容,自身也愿意努力学习,算法的学习过程并不困难。
4734
2020-03-02 17:18:04

零基础入门深度学习要了解什么内容?
如今,人工智能已经是一个频频被大众所提及的网络热词,但是不少人仍旧不知道人工智能并不等于深度学习。通常来说人工智能包括:机器学习、深度学习,它们之间有一定的交集但是我们一定要区分开它们。如果你是零基础想要入门深度学习,不妨一起来了解深度学习的概念、发展历程以及应用场景。
5039
2020-08-14 18:14:03

什么是人工智能
什么是人工智能?通过各种科幻影视剧,我们普遍认为人工智能就是通过各种方法最终实现,计算机模拟人类运行的系统。人工智能不是人的智能,但能够像人一样的思考,甚至有可能超过人的智能。
5005
2020-09-24 11:11:26
Apollo自动驾驶AI智能交通应用
综合政务数据、互联网数据、运营数据、物联网数据等基础上,通过人工智能算法对交通与土地相关性进行量化分析,并对交通资源进行优化配置。综合运用云计算、大数据、人工智能等跨领域技术。
4251
2020-10-22 09:39:24



