在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
现在是大数据的时代,也是数据爆炸的时代,如何处理大数据的存储成为了摆在人们面前的难题,因此分布式文件存储系统应用而生。同时分布式文件存储系统在大数据面试中,也是一个常常可以见到的考点之一。本文为大家梳理了相关的大数据知识点,感兴趣的小伙伴可以看一看。
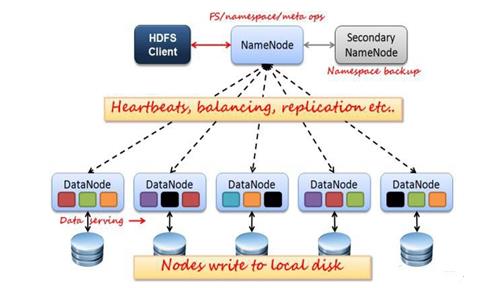
1、架构
如上图所示,HDFS也是按照 Master 和 Slave 的结构。分 NameNode、SecondaryNameNode、DataNode 这几个角色。
NameNode:是 Master 节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理 HDFS 的名称空间;
SecondaryNameNode:是一个小弟,分担大哥 namenode 的一部分工作量;是 NameNode 的冷备份;合并 fsimage 和 fsedits 然后再发给 namenode。
DataNode:Slave 节点,奴隶,干活的。负责存储 client 发来的数据块 block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)namenode 内存中存储的是=fsimage+edits。
SecondaryNameNode负责定时默认1小时,从namenode上,获取 fsimage 和 edits 来进行合并, 然后再发送给 namenode 。减少namenode 的工作量。
2、原理
(1)工作机制
NameNode 负责管理整个文件系统元数据;DataNode 负责管理具体文件数据块存储;Secondary NameNode 协助 NameNod进行元数据的备份。HDFS 的内部工作机制对客户端保持透明,客户端请求访问 HDFS 都是通过向 NameNode 申请来进行。
(2)读写流程
* HDFS 写数据流程
a、 client 发起文件上传请求,通过 RPC 与 NameNode 建立通讯,NameNode 检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
b、 client 请求第一个 block 该传输到哪些 DataNode 服务器上;
c、NameNode 根据配置文件中指定的备份数量及机架感知原理进行文件分配,返回可用的 DataNode 的地址如:A,B,C;注: Hadoop 在设计时考虑到数据的安全与高效,数据文件默认在 HDFS 上存放三份, 存储策略 为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份。
d、client 请求 3 台 DataNode 中的一台 A 上传数据(本质上是一个 RPC调用,建立 pipeline), A 收到请求会继续调用 B,然后 B 调用 C,将整个pipeline 建立完成,后逐级返回 client;
e、 client 开始往 A 上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),以 packet 为单位(默认 64K),A 收到一个 packet 就会传给 B,B 传给 C;A 每传一个 packet 会放入一个应答队列等待应答。
f、数据被分割成一个个 packet 数据包在 pipeline 上依次传输,在 pipeline 反方向上,逐个发送 ack(命令正确应答),最终由 pipeline 中第一个 DataNode 节点 A 将 pipeline ack 发送给 client;
g、 当一个 block 传输完成之后,client 再次请求 NameNode 上传第二个block 到服务器。
*HDFS 读数据流程
a、 Client 向 NameNode 发起 RPC 请求,来确定请求文件 block 所在的位置;
b、 NameNode 会视情况返回文件的部分或者全部 block 列表,对于每个block,NameNode 都会返回含有该 block 副本的 DataNode 地址;
c、 这些返回的 DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
d、 Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是DataNode,那么将从本地直接获取数据;
e、 底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
f、 当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
g、 读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
h、 read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回 Client 请求包含块的DataNode 地址,并不是返回请求块的数据;
i、 最终读取来所有的
3、API
(1)shell 定时采集数据至 HDFS
* 技术分析
HDFS SHELL:
hadoop fs -put // 满足上传 文件,不能满足定时、周期性传入。
Linux crontab: crontab -e
0 0 * * * /shell/ uploadFile2Hdfs.sh //每天凌晨 12:00 执行一次
* 实现流程
一般日志文件生成的逻辑由业务系统决定,比如每小时滚动一次,或者一定大小滚动一次,避免单个日志文件过大不方便操作。比如滚动后的文件命名为 access.log.x,其中 x 为数字。正在进行写的日志文件叫做 access.log。这样的话,如果日志文件后缀是 1\2\3 等数字,则该文件满足需求可以上传,就把该文件移动到准备上传的工作区间目录。工作区间有文件之后,可以使用 hadoop put 命令将文件上传。
以上就是大数据笔记之分布式文件存储系统的知识点梳理,大家有任何不懂的地方,都可以咨询博学谷的在线老师。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
云数据安全之数据加密的要点分析
下一篇:
如何成为一名优秀的云计算架构师?
相关推荐 更多

大数据Hadoop集群搭建步骤讲解
相信每一个大数据学习者都明白,Hadoop在大数据中的重要地位。Hadoop简称HDFS,它是是大数据的基础,所以大家一定要掌握好Hadoop的相关基础知识。本文主要是详细讲解Hadoop集群的基本概念、搭建步骤及注意事项。
6659
2019-08-22 16:18:16

做大数据开发累吗?需不需要加班?
做大数据开发累吗?需不需要加班?首先我们来了解大数据的工作内容,用一句话总结就是分析历史、预测未来、优化选择。总体上看来,大数据开发的工作需要按部就班进行,因此一般不需要加班,但是偶尔也会因为额外的需求增加以及对项目进度的把控而需要加班。不过,就与其它的研发技术岗位比较,大数据开发已经算是比较轻松的工作了。
16620
2019-09-16 10:10:54

ZooKeeper数据模型解析
ZooKeeper的数据模型采用树形层次结构,而Znode就是ZooKeeper树中的每个节点。和文件系统的目录树一样,ZooKeeper树中的每个节点可以拥有子节点。但也有不同之处: 比如Znode兼具文件和目录两种特点,而且它还具有原子性操作,存储数据大小也有限制。另外,Znode还是通过路径引用。下面我们来看看数据结构图、节点类型、节点属性以及ZooKeeper Watcher相关内容。
5111
2020-06-15 10:32:03

大数据软件学习入门技巧
大数据软件学习入门技巧,一般而言,在进行大数据处理时,会先使用大数据数据库,如 MongoDB、 GBase等。然后利用数据仓库工具,对数据进行清理、转换、处理,得出有价值的数据。接着用数据建模工具建模。最终用大数据工具进行可视化分析。
4399
2020-07-06 15:07:49

大数据可视化分析工具常用的有哪些?
企业基础数据才能制定出正确的策略,常用的分析工具有、Tableau、ECharts、Highcharts、魔镜、图表秀等。在大数据时代有价值的商品则是数据,大数据技术为决策提供依据,在政府、企业、科研项目等决策中扮演着重要的角色。
5347
2020-09-24 16:39:22



