在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
Spark作为一种分布式的计算框架,类似于大数据开发中Hadoop生态圈的MapReduce,计算思想和MR非常相似,两者都是分而治之的思想,但使用率要比MR高很多。本文整理了关于Spark运行架构的大数据面试题,内容包括Spark运行的基本流程、架构特点、优势。
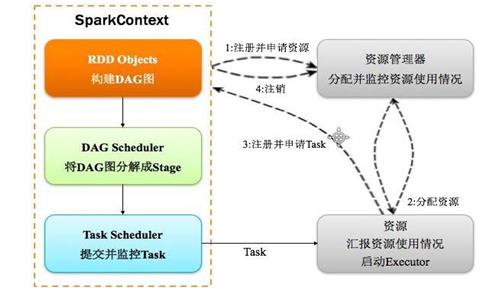
1、Spark 运行基本流程:
(1)构建 Spark Application 的运行环境(启动 SparkContext),SparkContext 向资源管理器(可以是 Standalone、Mesos 或 YARN)注册并申请运行 Executor 资源;
(2)资源管理器分配 Executor 资源并启动 Executor,Executor 运行情况将随着心跳发送到资源管理器上;
(3)SparkContext 构建成 DAG 图,将 DAG 图分解成 Stage,并把 Taskset发送给 Task Scheduler。Executor 向 SparkContext 申请 Task,Task Scheduler 将Task 发放给 Executor 运行同时 SparkContext 将应用程序代码发放给 Executor。
(4)Task 在 Executor 上运行,运行完毕释放所有资源。
2、Spark 运行架构特点:
(1)每个 Application 获取专属的 executor 进程,该进程在 Application 期间一直驻留,并以多线程方式运行 tasks。
(2)Spark 任务与资源管理器无关,只要能够获取 executor 进程,并能保持相互通信就可以了。
(3)提交 SparkContext 的 Client 应该靠近 Worker 节点(运行 Executor 的节点),最好是在同一个 Rack 里,因为 Spark 程序运行过程中 SparkContext 和Executor 之间有大量的信息交换;如果想在远程集群中运行,最好使用 RPC 将SparkContext 提交给集群,不要远离 Worker 运行 SparkContext。
(4)Task 采用了数据本地性和推测执行的优化机制。
3、Spark的优势:
(1)计算效率高
资源复用;粗粒度的资源调度。
(2)使用方便
支持使用多门语言来编写;提供了超过80多种方法来供我们使用。
(3)通用性强
Spark生态圈中的组件都是基于SparkCore封装起来的。
(4)适应性强
可以接受上百种数据源;可以运行在各种各样的资源调度框架上。
以上就是大数据面试题,所有关于Spark运行架构的内容,不知道对大家梳理Spark运行架构的知识点,有没有帮助?
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
云计算大数据培训哪家好?课程都学什么?
下一篇:
博学谷云计算大数据培训班课程怎么样?
相关推荐 更多

大数据面试:数据仓库工具hive面试题集锦
进入DATE时代,大数据技术成为互联网发展的核心要素之一。与此同时大数据开发工程师的薪资也成为行业内高薪的代表。想从事大数据开发需要掌握多种核心技术:Hadoop、Hive、Storm、Spark、Scala等等。而且这些技术知识点已经成为大数据工程师进入职场时面试中必备的考点。这里主要和大家分享一下数据仓库工具hive相关的面试题!
15868
2019-07-05 17:30:53

大数据kafka常见面试题整理附答案
kafka一直都是大数据面试题的必考点。因此,小编整理了有关kafka知识点的大数据面试题,主要针对kafka的定义、与传统消息系统的区别、kafka集群的安装与搭建三大问题,并附上了参考答案。需要梳理kafka知识点的同学可以看看。
10335
2019-08-06 16:23:49

如何激活conda环境?conda创建新环境步骤教程
如何激活conda环境?针对这个问题,本教程将手把手按照创建、激活、查看活跃的环境三个步骤教大家conda创建新环境。
28272
2019-08-07 15:38:03

大数据专业学习难度大吗?需要学习什么技术?
众所周知,大数据专业是目前互联网行业中高薪岗位之一。然而看到高薪的机会,大部分同学立刻行动投入大数据专业的学习中,也有一部分同学发表自己的疑问:大数据专业这样高薪是否学习难度非常大?如果从事大数据专业工作,需要学习什么技术呢?
13284
2019-09-02 19:04:37

大数据疑难解答 Hbase内部是什么机制?
众所周知,HBase是一个非关系型数据库,它的特征是分布式、列式存储、开源和版本化。无论是在大数据的面试中,还是大数据的工作中,这都是一个经常会出现的难题,然而却很少人能够说清Hbase内部机制。今天我们就花些时间聊聊Hbase内部是什么机制。
6912
2019-10-17 18:13:28



