

-
讲的很到位呀,知识点安排的很紧密,不拖拉

哲~
刚刚
-
233,李老师讲课很6嘛,被李老师的Kylin课程圈粉过来的,Kudu果然也没有让我失望

大熊
今日
-
课程安排很,从应用场景、安装部署、优化到案例一应具有,学完这个,对Kudu可以说是有个很的认识了

追风人
今日
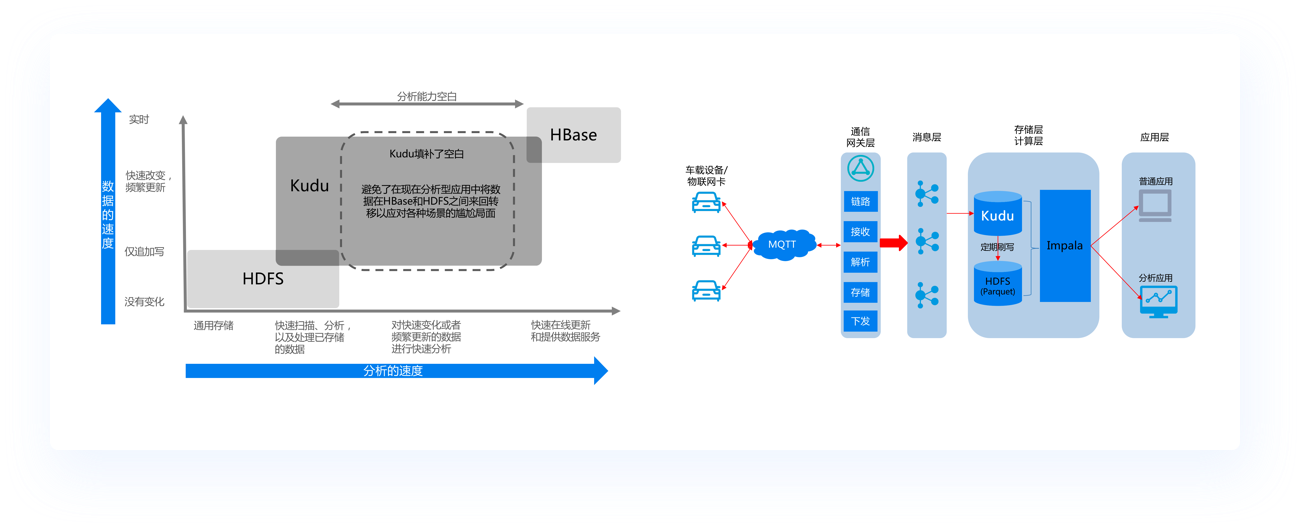
近年来的应用越来越广泛,在阿里、小米、网易等公司的大数据架构中都有着不可替代的地位。Kudu支持水平扩展和高可用,集HDFS的顺序读和HBase的随机读写于一身,同时具备高性能的随机写,以及很强大的可用性。
本课程对Kudu做了全方位的剖析,包括Kudu原理、架构、集群部署、Kudu优化技巧、表与模式设计等,最后结合一个物联网数据存储分析项目,介绍了在工作中如何进行表和模式设计,如何使用Kudu解决业务中应对大规模数据分析和随机读写问题。
基于Kudu
搞定海量物联网数据存储与分析


Kudu技术优势/应用场景


海量数据高并发随机读写及OLAP分析一站式解决方案
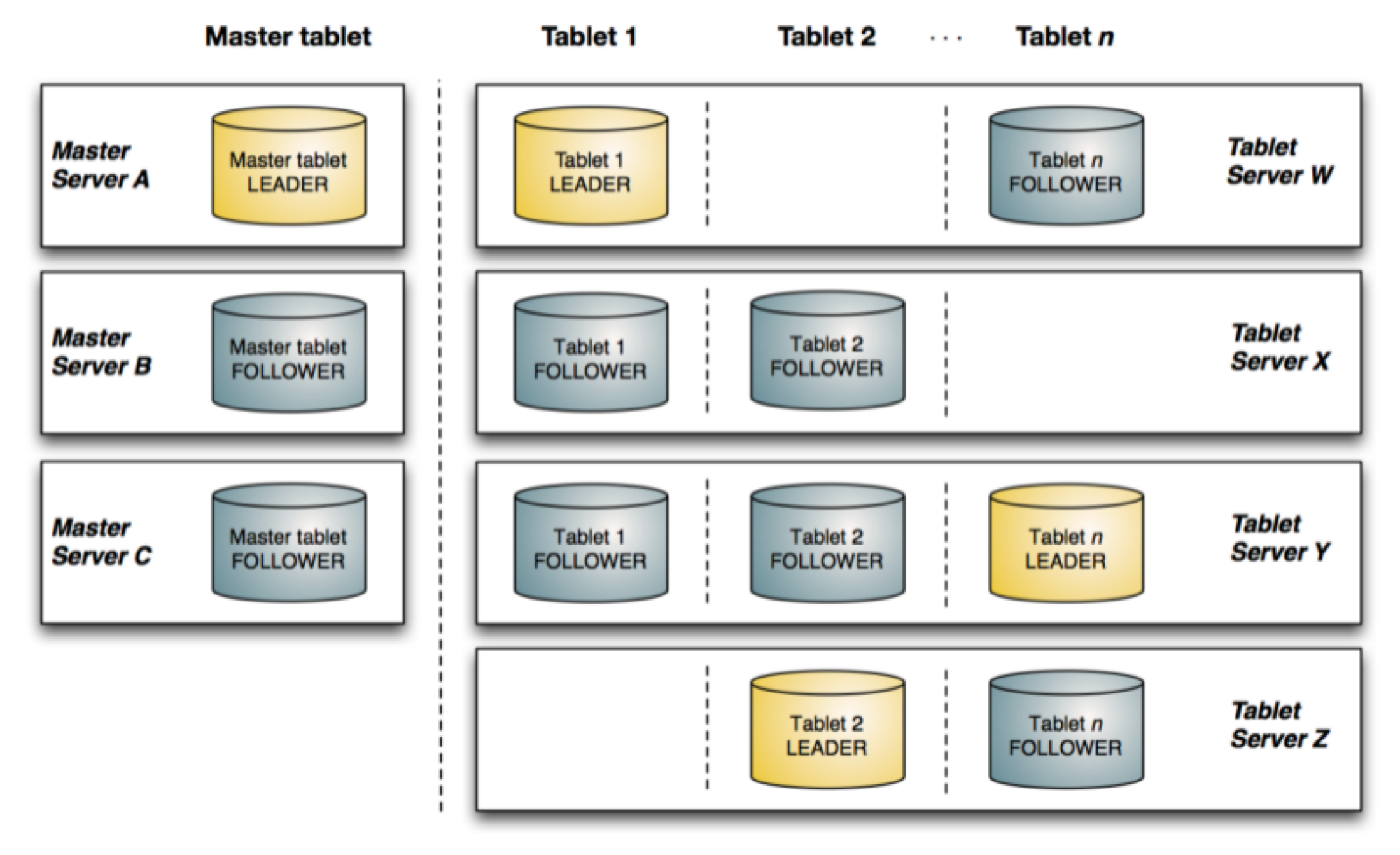
深入浅出的Kudu架构讲解
带你快速入坑Kudu,并完善自身对Hadoop存储层的应用认知
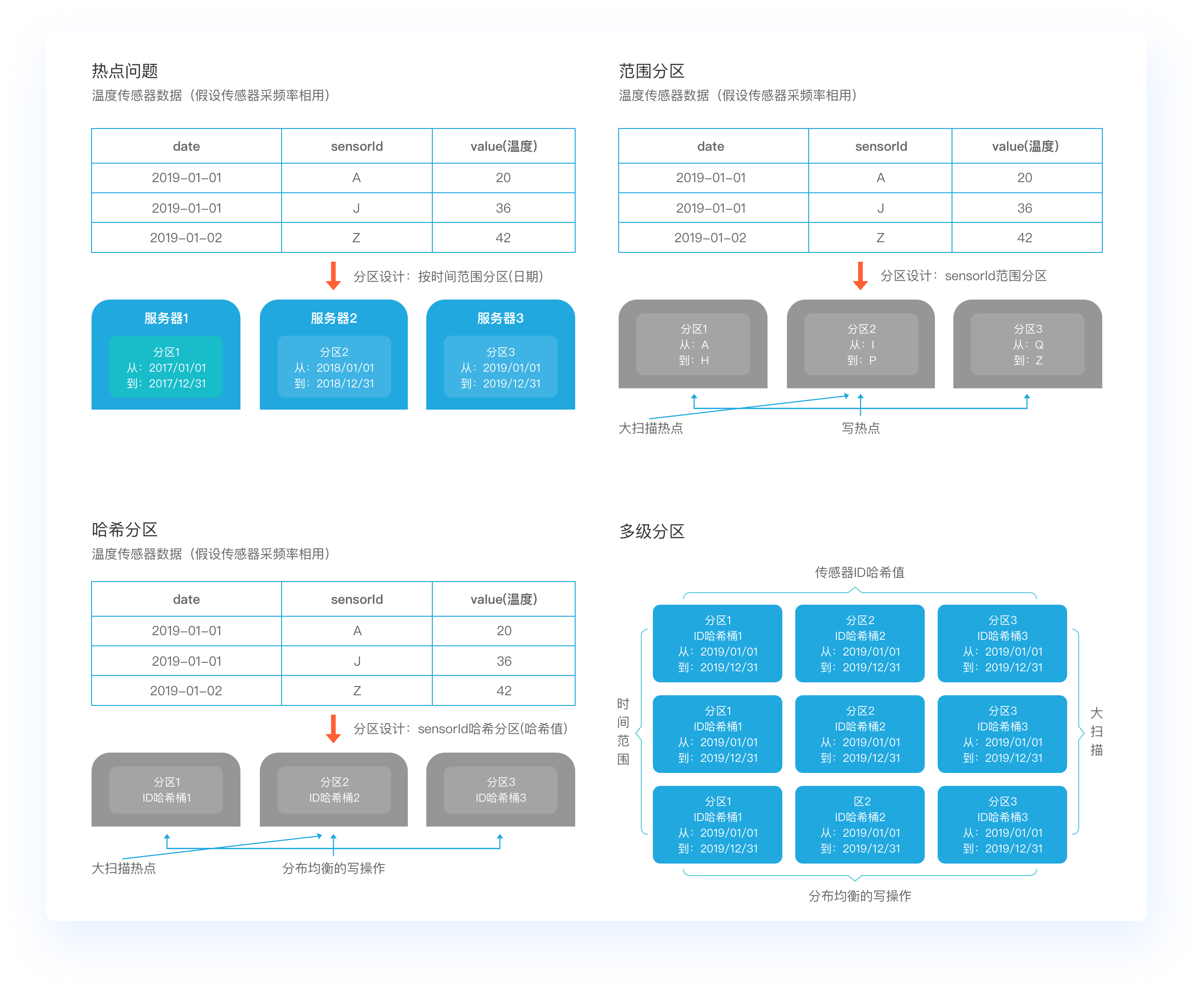
四个角度全方位解析表与模式设计技巧
手把手带你设计出稳定运行并拥有最佳性能的Kudu Schema
Kudu五大主题,四个层面的性能调优
助你掌握Kudu实用技巧

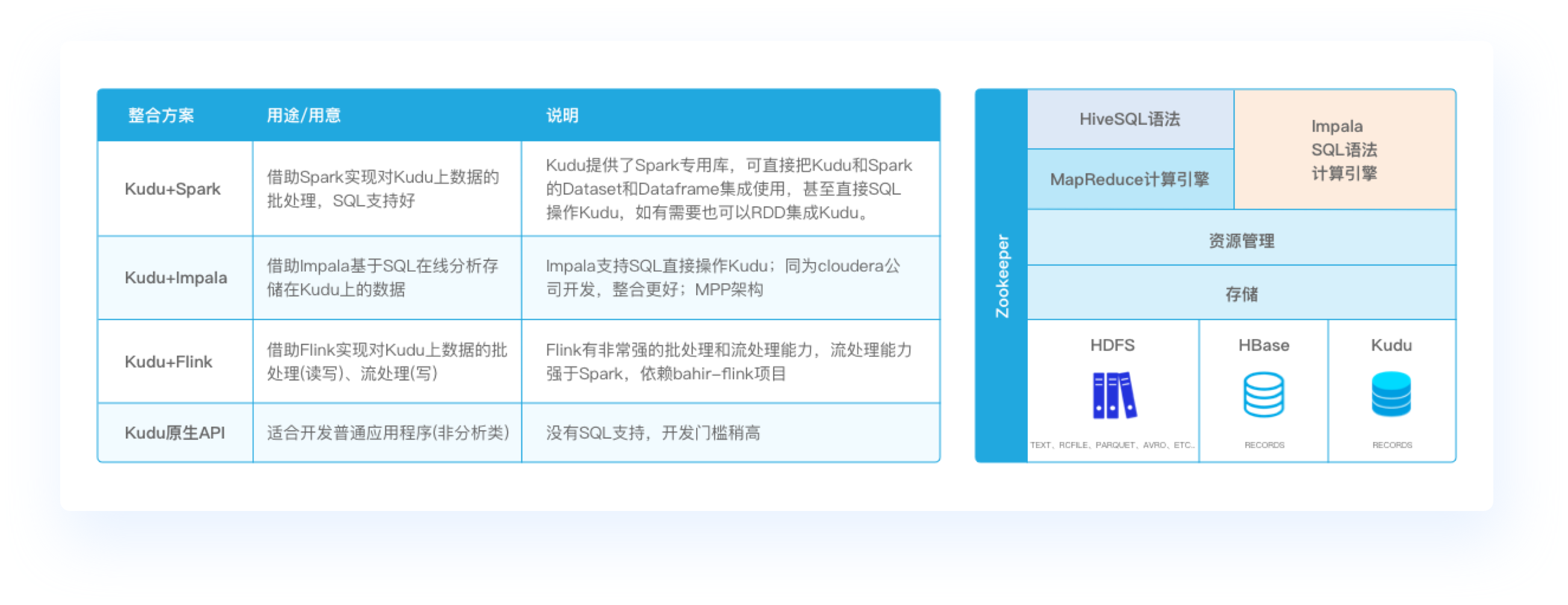
Kudu与Hadoop生态集成(集成Spark、集成Impala、集成Flink)
帮你看清Kudu在大数据生态的位置
基于Kudu实现物联网海量数据快速读写及分析
教你用一份数据搞定两个场景

掌握Kudu应用场景、架构及集群部署
01
02
构建Kudu和大数据生态其它流行组件的知识体系
快速入门Kudu开发编程接口、表与模式设计等问题
03
04
轻松应对工作中遇到的大规模数据分析、高并发随机读写等问题
深度理解Kudu读写原理、企业级调优技巧,可直接用于生产
05
06
通过海量物联网数据分析项目掌握Kudu在实际项目中的应用,在工作中可举一反三
-

适合人群
Suits the crowd
-
- 对OLAP感兴趣,最好有1年以上大数据相关工作经验
- 对Kudu有所了解,但缺乏系统的认知,在工作中使用Kudu做不到得心应手
- 工作中遇到大规模数据随机读取和快速分析等问题,不知道如何解决
-
- 了解Linux、Docker基本操作
- 有一定的HBase、Impala、Spark等大数据基础知识
-
技术储备
Technical reserve requirement






